Introduction to Web Application Security
A Prelude in Three Parts
Edward Z. Yang
MIT 2012
An Introduction
- Who am I?
- My name is Edward Z. Yang, I'm currently a Freshman at MIT, and I was lassoed into giving a class over IAP this year.
- Why should you listen to me?
- I'm the lead developer of the open-source package HTML Purifier, which was developed for the express purpose of anti-XSS. I've been working with web application security issues for some time now.
- What is Web Application Security?
- It's a somewhat nebulous, but the term is generally used to describe a specific class of security vulnerabilities common to applications deployed on the World Wide Web. Today's lecture will focus on XSS, SQL injections and CSRF, which compromise a majority of the vulnerabilities in web applications today.
Overview
- String is not a type
- Part One, covering simple XSS and SQL injection
- String filtering is crypto
- Part Two, covering complex XSS
- A browser sent a request, did the user mean to send it?
- Part Three, covering CSRF and clickjacking
Part 1: String is not a type
- What is XSS?
- Why is XSS bad?
- "How to stop XSS"
- String is not a type: Format and Context
- The Wrong Way, a Better Way, and the Right Way
- Practical considerations
- The Encoding Story
What is XSS?
- Cross-Site Scripting
- Violation of Same Origin Policy
- The Same Origin Policy is the foundation of web security, as it restricts the ability of web sites from accessing information from other web sites on different domains.
- External JavaScript running on your domain
- Thereby bypassing the Same-Origin policy.
<img alt="<?php echo $description ?>" />
- Let
$descriptionbe:"><script>xss();</script>
- Result:
<img alt=""><script>xss();</script>" />
Why is XSS bad?
- Session hijacking
- JavaScript on your domain can access document.cookie and steal active session cookies from your users.
- Compromised administrator accounts
- The above, where user = administrator.
- Web worms: Samy and friends
- JavaScript on your domain can send HTTP requests, and read the results too. That means that XSS could be used to propagate itself, making a big mess.
How to stop XSS?
- Remove "javascript" and "script" from input data?
- This is a common first impulse, but it's fundamentally the wrong way to approach the problem. What if a user legitimately needs to talk about JavaScript? Furthermore, it is very ineffective. We'll talk more about this in the second part of the lecture.
- Escape the data?
htmlspecialchars() // PHP CGI.escapeHTML() # Ruby cgi.escape() # Python
- This is the usual answer to this problem, and most web applications you see out there will be using some variant of these functions. While these functions are technically sufficient to prevent XSS, they are often misapplied. "Escape the data" is not the whole story.
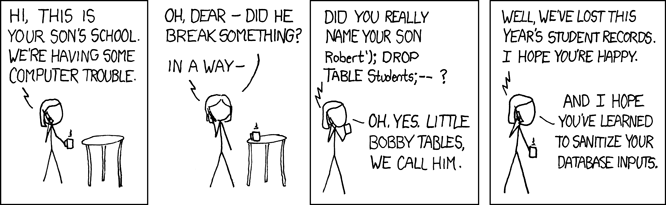
SQL injection is like XSS
(courtesy XKCD)
The anatomy of an SQL injection vulnerability is exactly the same as that of XSS, but instead of HTML, we're dealing with SQL (the effects are also different: with SQL injections an attacker can steal user data or destroy your database, but this is more based on the functionality of SQL versus HTML). The two are manifestations of a more general phenomenon.
String is not a type
What other information is needed to interpret strings in a web application?
A string is not just a string. Where the string is going, and what the format of contents of string is, are vital to understanding what can be safely done with a string.
What does your string contain?
Some possibilities:
- Plaintext
- Rich web formats
- HTML
- XML
- SQL
- JSON
- Rich non-web formats
- Rich Text Format
- LATEX
- Shell code
- Programming language X
Plaintext is the simplest story; it's benign and universal. We can then structure the text, adding extra information to it in the form of markup, so that we can do interesting things like make a word bold or initialize an array with four members (JSON).
Escaping is a format change
- Plaintext → X
- This is the simplest type of format change, since plaintext is the lowest denominator of all markup languages. All markup languages contain plaintext; however, one markup language may support a feature that another may not support.
- Plaintext → HTML
- Plaintext
<bob@example.com>
- HTML
<bob@example.com>
- An escaping function changes plaintext to X, while keeping the meaning the same.
- This may seem obvious, but it's a far better mental definition for "escaping" than "a function that replaces certain characters with their escape sequences."
Format is context sensitive
<img src="http://example.com" alt="Double-quoted text" />
<a title='Single-quoted text'>Regular text</a>
There are four distinct plaintext snippets in this block of code:
http://example.com(URL)Double-quoted textSingle-quoted textRegular text
Format is context sensitive (II)
Consider the following text snippets:
javascript:alert(1);- This is insecure as a URL, but is fine within the title/alt attributes and regular text.
He said "Oh no!"- Valid in regular text and single-quoted attributes, but invalid in double-quoted attributes.
You're funny- Valid in regular text and double-quoted attributes, but invalid in single-quoted attributes.
Example in SQL
Mixing up context in other languages is usually more obvious.
bob(plaintext) →bob(SQL)- The important point is that this is SQL wrapped in single quotes. What happens if you forget to put this string in quotes?
SELECT * FROM `users` WHERE `name`=bob;- ERROR 1054 (42S22): Unknown column 'bob' in 'where clause'
- MySQL thinks bob is a column, not a string, and in this particular table throws an unknown column error.
Quiz time!
Secure or not?
We're going to use a few PHP specific examples. For those
unfamiliar, htmlspecialchars() is an HTML escaping function
that is safe for double-quoted attributes and regular text, and
mysql_real_escape_string is an SQL escaping function.
Question 1
<?php echo htmlspecialchars($foo); ?>
Ostensibly secure, but it's a trick question.
Why is it a trick question? I haven't told you what
context I'm echoing $foo to; for all you know it might
be a terminal or a plaintext document. Nevertheless, for the next few questions,
assume that we're working in an HTML document.
Question 2
<a href="<?php echo htmlspecialchars($foo); ?>">
Insecure. We talked about this specific example earlier in the lecture!
Question 3
<?php echo mysql_real_escape_string($foo) ?>
Insecure.
Question 4
In a JavaScript file:
var variable = "<?php
echo htmlspecialchars($data);
?>";
Insecure. If you need
any convincing, consider what happens to backslashes in JavaScript. If
you need to output text in a context you're not familiar with, be sure
to check if there's an appropriate escaping function. In this case,
you should use json_encode() (without the quotes).
Side note: The above-mentioned use of JSON is not conforming, and there's some talk of changing the function in PHP. Buyer beware!
String is not a type: A summary
- Know your string's format.
- With plaintext strings, this is equivalent to "is the string escaped or not"?
- Know where your string is going.
- This includes both the destination format and the context within that format.
The wrong way
- Magic quotes. This is a particularly evil feature. For those lucky enough to never have to have dealt with this monstrosity, it's an old feature in PHP that helpfully escapes all of your input data for the database. That is, of course, assuming that your data is going to the database at all. The feature is slated to be removed in PHP6.
- In database, some is data escaped, some data is not escaped
- Data is escaped in domain logic. This means that the call to the escaping function is relatively far away from the point when it is output.
A setup like this makes it really difficult to answer the two questions we posed earlier. Did we escape it already? Do I have to de-escape and re-escape? What escaping function should I use? You shouldn't need to ask these questions.
A better way
- Delay escaping until the end
- Keep data unescaped in the database
- Treat data from trusted sources the same as user input.
- This can save your fanny if you think that
a particular environment variable is safe, but it actually isn't.
PHP_SELFis a particularly good example of this; an attacker can put arbitrary text in the URL and have it show up inPHP_SELF.
The right way
How do we, on a programmatic level, enforce the design principles in the previous slide?
- Ditch string concatenation
- Use an API that:
- Hides complexity
- If you were drawing a bitmap image programatically, you wouldn't individually output each of the pixels: you'd use a function to draw a line or typeset some text. If you pick a better API, you don't have to worry about the low level details and can focus on the high level concepts you wish to express.
- Makes it hard to do the wrong thing
- If you have to write out the escape function every time you need to output some text, you are bound to forget at some point. The point of (misguided) attempts to have everything escaped from the get-go is it removes this failure mode; however it's the wrong way to think about things.
For SQL: Bound Parameters
- Instead of:
mysql_query('SELECT * FROM users WHERE name=' . mysql_real_escape_string($name)); - Use:
$sql = 'SELECT * FROM users WHERE name = ?' $sth = $dbh->prepare($sql); $sth->execute(array($name)); - For many database client libraries, the concatenation never takes place: the values of the bound parameters are sent directly over the wire.
For HTML: DOM Builder
- Instead of:
$html = '<b>' . htmlspecialchars($text) . '</b>'; - Use:
$b = $doc->createElement('b'); $b->addChild( $doc->createTextNode($text) );
An added benefit of DOM builders, beyond security, is the fact that their output is guaranteed to be well-formed.
For Shell Code: Multiarg Exec
- Instead of (Python):
os.system("stella " + shellesc(name)) - Use:
subprocess.call(["stella", name])
For URLs: URL builder
- Instead of:
$url = 'index.php?name=' . urlencode($foo); - Use:
$query = http_build_query(array( 'name' => $foo )); $url = 'index.php?' . $query
This is, admittedly, not a great example. You'll appreciate URL builders more when you get a URL with an existing query string, and then you have to add another parameter to it. In that case, if you were given a string URL, you'd have to test append an ampersand and the new pair, unless your parameter already exists or if there are no query keypairs yet. With a builder, you simply write in the hash value, and then go your merry way.
Practical considerations
So if Safe APIs are so good, why hasn't everyone switched to using DOM builders yet?
- Verbose and difficult to use
- Not native
- Performance and memory usage
Verbose and difficult to use
Here is an example of writing HTML with concatenation:
<p> Welcome <em><?php echo htmlspecialchars($username) ?></em>. Here's a <a href="http://example.com">link</a> </p>
And a corresponding example with a DOM interface:
$p = $doc->createElement('p');
$p->appendChild($doc->createTextNode('Welcome '));
$em = $doc->createElement('em', $username);
$p->appendChild($em);
$p->appendChild($doc->createTextNode('. Here's a '));
$a = $doc->createElement('a', 'link');
$a->setAttribute('href', 'http://example.com');
$p->appendChild($a);
The DOM version is substantially longer and more difficult to understand.
Verbose and difficult to use (II)
Consider another function commonly used to format text entries:
<?php echo nl2br(htmlspecialchars($text)); ?>
The DOM equivalent is:
foreach (explode($text, "\n") as $i => $part) {
if ($i !== 0) $b->addChild($doc->createElement('br'));
$b->addChild($doc->createTextNode($part));
}
One last thing: DOM tools are XML-oriented, so expect a bit of post-processing, especially with XSLT
Verbose? Maybe you can fix it!
- In Perl with Template::Declare:
use Template::Declare::Tags; use base 'Template::Declare'; template simple => sub { p { outs "Welcome "; em { $username }; outs ". Here's a "; a { attr { href => 'http://example.com' } "link" }; } }; - Abuse language features!
- It's little surprise that one of the most prominent examples of DOM builder done right is written in Perl, known for its "There's more than one way to do it" mentality. Don't be bashful in using esoteric language features to get a natural, flowing interface. The task may be impossible in Java, but then again, Java was always fairly verbose to begin with.
- See also: Markaby for Ruby and XSLT
Not native
- At best, you might get libxml's API
- External libraries add overhead
- Dependency hell
- Unless you decide to package all of your external libraries with your application, you will have to deal with users hunting down libraries for your application and version number mismatches, with little incompatibilities that will drive you crazy.
- Incompatible upstream changes
- Ever upgrade an external library and suddenly discover that nothing works anymore? Like it or not, APIs change, and this means extra maintenance cost for your application. Nobody likes having to update their code because someone renamed a method.
- Reduced portability
- If you ever decide you want to port your application to another language, you must find an equivalent library in the destination language, or port the library yourself. Additionally, if the language you currently use has a diverse ecosystems of versions (cough PHP), the versions you are able to target are limited by your least compatible external library.
- Yak shaving: coding one yourself
Performance and memory usage
- DOM can't be streamed
- The entirety of a DOM object must be stored in memory at any given time. This is opposed to string concatenation, which you can buffer and send off to the client in chunks.
- DOM has memory overhead from data structures
- A string will need maybe one more byte to indicate its length (zero if you're null terminated). Each object in your DOM tree, however, carries an associated overhead as all objects do. And with a large document, that means a lot of objects, and a lot of overhead. It's not surprising for the in memory representation of a several megabyte XML document to reach the gigabytes scale.
- DOM needs to be serialized
- Even after your DOM has been created, you still have to squash it into a string to send over the wire. Admittedly, this is one of the less costly operations, but it's an extra step not present with normal concatenation.
- Solution: Use caching
- Caching is your friend. Squid is your friend. Even if you think you have a highly dynamic website, pages you serve will persist one or two minutes before being updated. Make the DOM building a one-time cost for those two minutes, and you will be able to do great things.
The Encoding Story
What is text?
Numbers given form (ASCII)
| 01001000 | 01100101 | 01111001 |
| 0x48 | 0x65 | 0x79 |
| H | e | y |
Multibyte encodings (UTF-8)
| 00110101 | 11000010 | 10100010 |
| 0x35 | 0xC2 | 0xA2 |
| 5 | ¢ | |
I'm not here to evangelize UTF-8/Unicode, but use it!
Why should you care?
- Text in a multibyte encoding can be malformed
- Malformed text can lead to XSS
- Certain codepoints (i.e. characters) are not valid HTML/XML
- XML parsers may show the tan screen of death
- It makes good sense to validate your text, much like you validate emails or numbers
Checking for Well-Formedness
- If a language has a "Unicode string":
- As long as you use those strings, it's done automatically
- If not:
- There might be a built-in function:
decode_utf8()in Perl - You can abuse iconv:
iconv('UTF-8', 'UTF-8//IGNORE', $text) - Or finally, do it yourself
- There might be a built-in function:
Checking for invalid codepoints
- ISO control characters (minus whitespace):
U+0000 to U+0008, U+000B, U+000C, U+000E to U+001F, U+007F to U+009F - Surrogates: U+D800 to U+DFFF
- Noncharacters: U+FDD0 to U+FDDF, U+FFFE, U+FFFF, U+1FFFE, U+1FFFF, U+2FFFE, U+2FFFF, U+3FFFE, U+3FFFF, U+4FFFE, U+4FFFF, U+5FFFE, U+5FFFF, U+6FFFE, U+6FFFF, U+7FFFE, U+7FFFF, U+8FFFE, U+8FFFF, U+9FFFE, U+9FFFF, U+AFFFE, U+AFFFF, U+BFFFE, U+BFFFF, U+CFFFE, U+CFFFF, U+DFFFE, U+DFFFF, U+EFFFE, U+EFFFF, U+FFFFE, U+FFFFF, U+10FFFE, and U+10FFFF
Bold codepoints are not permitted in XML; italicized codepoints are not permitted in XML but are permitted in HTML (such is the strange story of the form feed). If you want to be safe, nuke all of these codepoints.
A quick note on implementing a function that removes
these invalid codepoints: your regular expressions library probably has
native support for Unicode, so use expressions like \x{FFFE}
to match noncharacters and strip them out.
Part 2: String filtering is crypto
- What is the problem?
- How might one solve it?
- Why you don't want to DIY
- How to shop for a filter library
- How to format shift
Expanding the scope
- Previously: plaintext → X
- What about X → Y?
- More checks are needed, since X can now express harmful content, but "be valid".
How to do it?
Don't.
Why?
It's complicated.
What is not safe?
- JavaScript
- This one is pretty obvious, but what is less obvious is "Where can JavaScript be found?" There are a lot of places, from JavaScript URLs to expression() in CSS.
- Something new is the fact that there are libraries such as Google Caja in development which are for taking untrusted JavaScript and making it safe.
- Embedded/active content
- If you add certain attributes, you may make things more safe, but you need specific attributes for specific types of content (separate types for Quicktime, Flash, etc.)
- Forms
- This one is not strictly a security risk, but it's
very difficult to do correctly. Forms have ridiculous potential for
phishing, especially because they can overlay or emulate trusted form
elements on a website. One possible mitigation factor is to intercept
the
actionattribute and have the form point to a page which warns the user that the information they submitted is leaving the website. - And more... this is a bad question
What is safe?
- Whitelisting is the key
- Anything you allow, you must know to be safe in all browsers
- Things to whitelist:
- Tag names
- Attribute names
- Attribute values
- CSS properties
- CSS values
- URI schemes
- Syntax
Syntax?
- Not all text is valid HTML
- Benefits of validity:
- Valid HTML is unambiguous
- Invalid HTML behavior varies among browsers
- Parse and reserialize
How to do it (for HTML → HTML)
- Parse into a DOM
- Walk the DOM tree, and:
- Flatten non-whitelisted elements
- Flatten means removing the contents of a node and
placing them in the parent node, and then removing the original
node. This converts
<blink>Foo</blink>toFoo, which is more user-friendly. - Remove non-whitelisted element and attribute pairs
- Validate the attribute values
- This part is non-trivial, since the contents of an attribute can be arbitrarily complex.
- Optional: Move around nodes to get standards compliance
- Reserialize
Some numbers
- 91 tag names
- 188 distinct attributes
- 98 CSS properties
- Happy coding!
Shopping for a filter library
- Does it use a whitelist?
- Does it parse the HTML?
- Does it check attributes?
- Does it pass the XSS cheatsheet?
- Is it well known and widely used?
First off, a disclaimer: I wrote a filter library, so I'm a little partial in this domain. Still, I think this is a pretty good smoketest for evaluating a filter library. 1-3 deal with fundamental architectural decisions, 4 is a practical test and 5 is good to have, because it means that updates will be released more frequently and that the library has had more eyes on it. Missing one of these is not grounds for excluding a library, but certainly be more cautious in such circumstances.
Integration
- HTML filtering is expensive; cache the output.
- With a DOM builder:
- Find a library that uses DOMs, and import its result nodes into your document
- Otherwise, you'll have to parse again
And remember...
Update, update, update.
This is especially important if the filter is blacklist based, since new attacks will be discovered.
Format shifting
HTML isn't exactly the most user-friendly format, so you'll often want to offer another language like BBCode, Markdown, Textile or Wikitext. In such cases:
- Use the canonical implementation
- There will usually only be one implementation of the language your looking at supporting. Don't reinvent the wheel; use it!
- Some languages (Markdown esp.) don't protect against XSS; you'll still need an HTML filtering library
- This will be really obvious, but make sure you test for it!
- A BBCode convertor is just like an HTML filter
- Look for the same traits when evaluating them.
Part 3: Request Forgery
- The assumption
- How to forge a GET request
- How to forge a POST request
- CSRF protection
- Protection in practice
- ClickJacking
- ClickJacking protection
The assumption
- You've recieved a request:
- It comes from your user's IP address
- It has a valid session cookie
- It has the same browser signature
- It has the same referer
- Is it forged? It could be.
How to forge a GET request
<img src="http://example.com/logout.php" />
Okay... pretty easy you say...
How to forge a POST request
<script type="text/javascript">
var xhr = new XmlHttpRequest();
xhr.open("POST", "http://example.com/post.php", true);
xhr.setRequestHeader("Content-Type",
"application/x-www-form-urlencoded");
xhr.send('evil=data');
</script>
Also doable with an autosubmitting form. And yes, I know that code isn't portable. This isn't a class on how to haxor websites.
CSRF protection
- A request can be forged, but the attacker can't see the resulting page
- Use a token/nonce:
- Random value associated with user session
- Placed in a hidden field in the form
- Value from request checked with expected value
<form method="post" action="logout.php">
<input type="submit" name="logout" value="Log out">
<input type="hidden" name="token" value="RANDOM">
</form>
Protection in practice
- You have a lot of forms
- Too many to add this to all
- If form generation is centralized, add the code there
- Otherwise, consider dynamically rewriting output HTML to add CSRF fields to all forms
Protection in practice (II)
- AJAX: Put the token in inline javascript
- Putting it in an external JavaScript file
defeats the purpose, since the attacker can read it using a
<script>tag. - Session tokens can mess up Squid caches: use Tim Starling's X-Vary-Options patch
- Requiring a session cookie messes up anonymous users with cookies off
- This problem assumes you want to support anonymous users. There's not much you can do about this without degrading security. A clever implementation, however, might only enable anonymous functionality if cookies are not present at all.
ClickJacking
And now, something new
The elegance of this attack is the fact that it bypasses all of the previous protections we may have put up for CSRF: the user is actually physically clicking on the link or submit button, and there is no way to tell if it was intentional or not. It is like slightly like social engineering, but unlike in that the actions a user may make are completely reasonable.
ClickJacking protection
- ClickJacking is built off of the iframe element
- Use a framebuster:
<script type="text/javascript"> if (top != self) { top.location.href = self.location.href; } </script> - Make sure your site doesn't use frames!
Questions?
Questions?