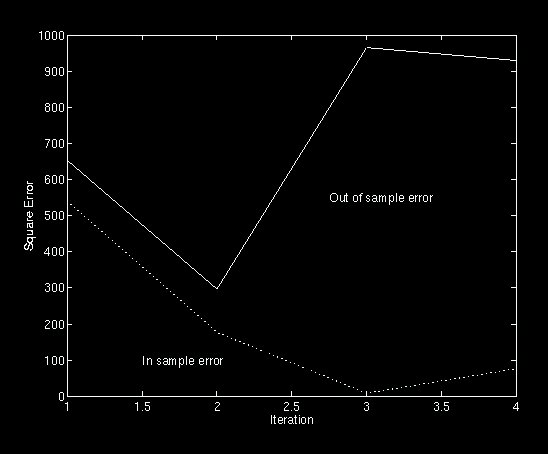
Figure 1: In and out of sample errors
To confirm the system was working, a working/resting dataset was run through it, and, as expected, it yielded a discriminator based primarily on velocity. Though not visually apparent, heartrate data was also a substantial component of this discriminator.
The training data for the attack/non-attack classifier was composed of 3400 points encompassing one and a half days of activity for a single soldier, including extended marching periods, resting periods and an assault on a training target. Approximate times for the beginning and end of each of these activities had been logged and were used to tag the two states for the training data. This model was run with 15 experts on a smoothed four-dimensional input space composed of horizonal speed, vertical velocity, heart rate, and body temperature.
An out-of-sample data set from a third day of excercises composed of 1900 points encompassing a full day including two training assaults and intermediate rest and marching periods was used for cross validation.
As seen in Figure 1, after the second iteration the out-of-sample error was minimized. As expected, errors on the in-sample data were extremely low, and the errors on the out-of-sample data were reasonable.
Figure 1: In and out of sample errors
Figure 2 shows a graph of the estimated probability that the soldier was engaged in an assault scenario (blue), along with the actual probability (red). Looking at this graph, it appears that the first assault extended roughly twelve minutes past the logged end time, and the second assault started roughly ten minutes before the logged start time. Both of these observations would be consistent with errors in the event log. The person who recorded the log indicated that the actual times may be as much as 20 minutes off from the recorded values.
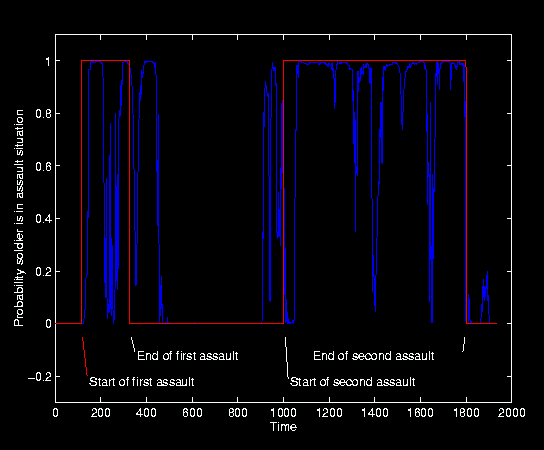
Figure 2: Probability soldier is currently engaged in an assault scenario
Overall, the discriminator performed very well. Further improvements could be made in performance, input space representation, more accurate collection of event logs, and using covariances instead of seperable Gaussians.
Next: About this document
Up: Cluster Weighted Modelling: A
Previous: Model Overview