Programming, using and understanding

Pike
Pike
Chapter one is devoted to background information about Pike and this book. It is not really necessary to read this chapter to learn how to use and program Pike, but it might help explain why some things work the way they do. It might be more interesting to re-read the chapter after you have learned the basics of Pike programming. Chapter two is where the action starts. It is a crash course in Pike with examples and explanations of some of the basics. It explains the fundamentals of the Pike data types and control structures. The systematic documentation of all Pike capabilities starts in chapter three with a description of all control structures in Pike. It then continues with all the data types in chapter four and operators in chapter five. Chapter six deals with object orientation in Pike, which is slightly different than what you might be used to.
When ĄLPC became usable, InformationsVõvarna AB started using it for their web-server. Before then, Roxen (then called Spinner) was non-commercial and written in LPC4. Then in 1996 I started working for InformationsVõvarna developing ĄLPC for them. We also changed the name of ĄLPC to Pike to get a more commercially viable name.
First you need to have Pike installed on your computer. See appendix E "How to install Pike" if this is not already done. It is also vital for the first of the following examples that the Pike binary is in your UNIX search path. If you have problems with this, consult the manual for your shell or go buy a beginners book about UNIX.
The arguments to main are taken from the command line when the
Pike program is executed. The first argument, argc, is how many
words were written on the command line (including the command itself) and
argv is an array formed by these words.
Also note the comments:
We have already seen an example of the if statement:
Note for beginners: go back to our first example and make sure you
understand what if does.
Another very simple control structure is the while statement:
1.1 Your first Pike program
int main()
Let's call this file hello_world.pike, and then we try to run it:
{
write("hello world\n");
return 0;
}
$ pike hello_world.pike
hello world
$
Pretty simple, Let's see what everything means:
int main()
This begins the function main. Before the function name the type of value
it returns is declared, in this case int which is the name of the
integer number type in Pike. The empty space between the
parenthesis indicates that this function takes no arguments.
A Pike program has to contain at least one function, the main function. This function is where program execution starts and thus the function from which every other function is called, directly or indirectly. We can say that this function is called by the operating system.
Pike is, as many other programming languages, built upon the concept of functions, i.e. what the program does is separated into small portions, or functions, each performing one (perhaps very complex) task. A function declaration consists of certain essential components; the type of the value it will return, the name of the function, the parameters, if any, it takes and the body of the function. A function is also a part of something greater; an object. You can program in Pike without caring about objects, but the programs you write will in fact be objects themselves anyway.
Now let's examine the body of main;
{
Within the function body, programming instructions, statements, are grouped together in blocks. A block is a series of statements placed between curly brackets. Every statement has to end in a semicolon. This group of statements will
be executed every time the function is called.
write("hello world\n");
return 0;
}write("hello world\n");
The first statement is a call to the builtin function write. This will
execute the code in the function write with the arguments as input data.
In this case, the constant string hello world\n is sent.
Well, not quite. The \n combination corresponds to the newline
character.
write then writes this string to stdout when executed. Stdout is the standard Unix output channel, usually the screen.
return 0;
This statement exits the function and returns the value zero. Any statements
following the return statements will not be executed.
1.2 Improving hello_world.pike
Typing pike hello_world.pike to run our program may seem a bit
unpractical. Fortunately, Unix provides us with a way of automating this
somewhat. If we modify hello_world.pike to look like this:
#!/usr/local/bin/pike
And then we tell UNIX that hello_world.pike is executable so we can run
hello_world.pike without having to bother with running Pike:
int main()
{
write("hello world\n");
return 0;
}
$ chmod +x hello_world.pike
$ ./hello_world.pike
hello world
$
N.B.: The hash bang (#!) must be first in the file, not even whitespace is allowed to precede it!
The file name after the hash bang must also be the complete file name to the Pike binary, and it may not exceed 30 characters.
1.3 Further improvements
Now, wouldn't it be nice if it said Hello world! instead of hello world ?
But of course we don't want to make our program "incompatible" with the old
version. Someone might need the program to work like it used to.
Therefore we'll add a command line option that will make it type the old
hello world. We also have to give the program the ability to choose
what it should output based on the command line option.
This is what it could look like:
#!/usr/local/bin/pike
Let's run it:
int main(int argc, string *argv)
{
if(argc > 1 && argv[1]=="--traditional")
{
write("hello world\n");
}else{
write("Hello world!\n");
}
return 0;
}
$ chmod +x hello_world.pike
$ ./hello_world.pike
Hello world!
$ ./hello_world.pike --traditional
hello world
$
What is new in this version, then?
int main(int argc, string *argv)
In this version the space between the parenthesis has been filled.
What it means is that main now takes two arguments.
One is called argc, and is of the type int.
The other is called argv and is a an array of strings.
A perhaps better way to represent an array of strings would be
array(string) which is exactly the same as string *
and probably easier to understand. The syntax string *
is more like the syntax in C/C++ however.
if(argc > 1 && argv[1] == "--traditional")
This is an if-else statement, it will execute what's between the first set
of brackets if the expression between the parenthesis evaluate to something
other than zero. Otherwise what's between the second set of brackets will
be executed. Let's look at that expression:
{
write("hello world\n");
}else{
write("Hello world!\n");
}argc > 1 && argv[1] == "--traditional"
Loosely translated, this means: argc is greater than one, and the second
element in the array argv is equal to the string --traditional. Since
argc is the number of words on the command line the first part is true only
if there was anything after the program invocation.
write("hello world\n");
The // begins a comment which continues to the end of the line.
Comments will be ignore by the computer when it reads the code.
This allows to inform whoever might read your code (like yourself) of
what the program does to make it easier to understand.
Comments are also allowed to look like C-style comments, ie. /* ... */, which can extend over several lines. The // comment only extends to the end of the line.
1.4 Control structures
The first thing to understand about Pike is that just like any other
programming language it executes one piece of code at a time. Most of
the time it simply executes code line by line working its way downwards.
Just executing a long list of instructions is not enough to make an interesting
program however. Therefore we have control structures to make Pike
execute pieces of code in more interesting orders than from top to bottom.
if( expression )
if simply evaluates the expression and if the result is true it
executes statement1, otherwise it executes statement2. If you have no need for
statement2 you can leave out the whole else part like this:
statement1;
else
statement2;if( expression )
In this case statement1 is evaluated if expression is true, otherwise
nothing is evaluated.
statement1;while( expression )
This statement evaluates expression and if it is found to be true it
evaluates statement. After that it starts over and evaluates expression
again. This continues until expression is no longer true. This type of
control structure is called a loop and is fundamental to all
interesting programming.
statement;1.5 Functions
Another control structure we have already seen is the function.
A function is simply a block of Pike code that can be executed with different arguments from different places in the program.
A function is declared like this:
modifiers type name(type name1, type name2, ...)
The modifiers are optional. See section 6.8 "Modifiers" for more details about
modifiers. The type specifies what kind of data the function returns.
For example, the word int would signify that the function returns
an integer number. The name is used to identify the function when
calling it. The names between the parenthesis are the arguments to the
function. They will be defined as local variables inside the function. Each
variable will be declared to contain values of the preceding type.
The three dots signifies that you can have anything from zero to 256 arguments
to a function. The statements between the brackets are the function
body. Those statements will be executed whenever the function is called.
{
statements
}
Example:
int sqr(int x) { return x*x; }This line defines a function called sqr to take one argument of the type int and also returns an int. The code itself returns the argument multiplied by itself. To call this function from somewhere in the code you could simply put: sqr(17) and that would return the integer value 289.
As the example above shows, return is used to specify the return value of a function. The value after return must be of the type specified before the function name. If the function is specified to return void, nothing at all should be written after return. Note that when a return statement is executed, the function will finish immediately. Any statements following the return will be ignored.
There are many more control structures, they will all be described in a later chapter devoted only to control structures.
arr=({1,2,3});Or, if you have already created an array, you can change the values in the array like this: This sets entry number ind in the array arr to data. ind must be an integer. The first index of an array is 0 (zero). A negative index will count from the end of the array rather than from the beginning, -1 being the last element. To declare that a variable is an array we simply type array in front of the variable name we want:
array i;We can also declare several array variables on the same line:
string i, j;If we want to specify that the variable should hold an array of strings, we would write:
array (string) i;
| newline | |
| carriage return | |
| tab | |
| backspace | |
| " (quotation character) | |
| \ (literal backslash) |
map=([five:good, ten:excellent]);You can also set that data by writing map[five]=good. If you try to set an index in a mapping that isn't already present in the mapping it will be added as well.
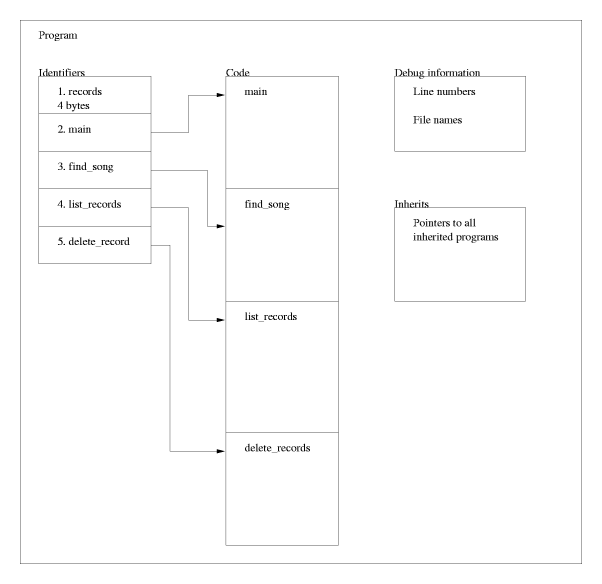
#!/usr/local/bin/pikeWe want to be able to get a simple list of the records in our database. The function list_records just goes through the mapping records and puts the indices, i.e. the record names, in an array of strings, record_names. By using the builtin function sort we put the record names into the array in alphabetical order which might be a nice touch. For the printout we just print a header, "Records:", followed by a newline. Then we use the loop control structure for to traverse the array and print every item in it, including the number of the record, by counting up from zero to the last item of the array. The builtin function sizeof gives the number of items in an array. The printout is formatted through the use of sprintf which works more or less like the C function of the same name.
mapping (string:array(string)) records =
([
"Star Wars Trilogy" : ({
"Fox Fanfare",
"Main Title",
"Princess Leia's Theme",
"Here They Come",
"The Asteroid Field",
"Yoda's Theme",
"The Imperial March",
"Parade of the Ewoks",
"Luke and Leia",
"Fight with Tie Fighters",
"Jabba the Hut",
"Darth Vader's Death",
"The Forest Battle",
"Finale"
})
]);
void list_records()If the command line contained a number our program will find the record of that number and print its name along with the songs of this record. First we create the same array of record names as in the previous function, then we find the name of the record whose number (num) we gave as an argument to this function. Next we put the songs of this record in the array songs and print the record name followed by the songs, each song on a separate line.
{
int i;
array (string) record_names=sort(indices(records));
write("Records:\n");
for(i=0;i<sizeof(record_names);i++)
write(sprintf("%3d: %s\n", i+1, record_names[i]));
}
void show_record(int num)The main function doesn't do much; it checks whether there was anything on the command line after the invocation. If this is not the case it calls the list_records function, otherwise it sends the given argument to the show_record function. When the called function is done the program just quits.
{
int i;
array (string) record_names = sort(indices (records));
string name=record_names[num-1];
array (string) songs=records[name];
write(sprintf("Record %d, %s\n",num,name));
for(i=0;i<sizeof(songs);i++)
write(sprintf("%3d: %s\n", i+1, songs[i]));
}
int main(int argc, array (string) argv)
{
if(argc <= 1)
{
list_records();
} else {
show_record((int) argv[1]);
}
}
2.1.1 add_record()
Using the builtin function readline() we wait for input which will be put into the variable record_name. The argument to readline() is printed as a prompt in front of the user's input. Readline takes everything up to a newline character.
Now we use the control structure while to check whether we should continue inputting songs.
The while(1) means "loop forever", because 1 is always true.
This program does not in fact loop forever, because it uses return
to exit the function from within the loop when you type a period.
When something has been read into the variable song it is checked.
If it is a "." we return a null value that will be used in the while statement to indicate that it is not ok to continue asking for song names.
If it is not a dot, the string will be added to the array of songs for this record, unless it's an empty string.
Note the += operator. It is the same as saying
records[record_name]=records[record_name]+({song}).
void add_record()
{
string record_name=readline("Record name: ");
records[record_name]=({});
write("Input song names, one per line. End with '.' on its own line.\n");
while(1)
{
string song;
song=readline(sprintf("Song %2d: ",
sizeof(records[record_name])+1));
if(song==".")
return;
if (strlen(song))
records[record_name]+=({song});
}
}2.1.2 main()
The main function now does not care about any command line arguments.
Instead we use readline() to prompt the user for instructions
and arguments. The available instructions are "add", "list" and "quit".
What you enter into the variables cmd and args is checked in the
switch() block. If you enter something that is not covered
in any of the case statements the program just silently ignores it and
asks for a new command.
In a switch() the argument (in this case cmd) is checked in the case statements. The first case where the expression equals cmd (the argument) then executes the statement after the colon. If no expression is equal, we just fall through without any action.
The only command that takes an argument is "list" which works like the first version of the program.
If "list" receives an argument that record is shown along with all the songs
on it. If there is no argument it shows a list of the records in the database.
When the program returns from either of the listing functions, the break instruction tells the program to jump out of the switch() block.
"Add" of course turns control over to the function described above.
If the command given is "quit" the exit(0) statement stops the execution of the program and returns 0 (zero) to the operating systems, telling it that everything was ok.
int main(int argc, array(string) argv)
{
string cmd;
while(cmd=readline("Command: "))
{
string args;
sscanf(cmd,"%s %s",cmd,args);
switch(cmd)
{
case "list":
if((int)args)
{
show_record((int)args);
} else {
list_records();
}
break;
case "quit":
exit(0);
case "add":
add_record();
break;
}
}
}
2.2.1 save()
First we clone a Stdio.File program to the object o.
Then we use it to open the file whose name is given in the string file_name for writing.
We use the fact that if there is an error during opening, open() will return a false value which we can detect and act upon by exiting.
The arrow operator (->) is what you use to access methods and variables in an object.
If there is no error we use yet another control structure, foreach, to go through the mapping records one record at a time.
We precede record names with the string "Record: " and song names with "Song: ".
We also put every entry, be it song or record, on its own line by adding a newline to everything we write to the file.
Finally, remember to close the file.
void save(string file_name)
{
string name, song;
object o;
o=Stdio.File();
if(!o->open(file_name,"wct"))
{
write("Failed to open file.\n");
return;
}
foreach(indices(records),name)
{
o->write("Record: "+name+"\n");
foreach(records[name],song)
o->write("Song: "+song+"\n");
}
o->close();
}2.2.2 load()
The load function begins much the same, except we open the file named file for reading instead.
When receiving data from the file we put it in the string file_contents.
The absence of arguments to the method o->read means that the reading should not end until the end of the file.
After having closed the file we initialize our database, i.e. the mapping records. Then we have to put file_contents into the mapping and we do this by splitting the string on newlines (cf. the split operator in Perl) using the division operator. Yes, that's right: by dividing one string with another we can obtain an array consisting of parts from the first. And by using a foreach statement we can take the string file_contents apart piece by piece, putting each piece back in its proper place in the mapping records.
void load(string file_name)
{
object o;
string name="ERROR";
string file_contents,line;
o=Stdio.File();
if(!o->open(file_name,"r"))
{
write("Failed to open file.\n");
return;
}
file_contents=o->read();
o->close();
records=([]);
foreach(file_contents/"\n",line)
{
string cmd, arg;
if(sscanf(line,"%s: %s",cmd,arg))
{
switch(lower_case(cmd))
{
case "record":
name=arg;
records[name]=({});
break;
case "song":
records[name]+=({arg});
break;
}
}
}
}2.2.3 main() revisited
main() remains almost unchanged, except for the addition of two case statements with which we now can call the load and save functions. Note that you must provide a filename to load and save, respectively, otherwise they will return an error which will crash the program.
case "save":
save(args);
break;
case "load":
load(args);
break;2.3 Completing the program
Now let's add the last functions we need to make this program useful: the ability to delete entries and search for songs.
2.3.1 delete()
If you sell one of your records it might be nice to able to delete that entry from the database. The delete function is quite simple.
First we set up an array of record names (cf. the list_records function).
Then we find the name of the record of the number num and use the builtin function m_delete() to remove that entry from records.
void delete_record(int num)
{
array(string) record_names=sort(indices(records));
string name=record_names[num-1];
m_delete(records,name);
}2.3.2 search()
Searching for songs is quite easy too. To count the number of hits we declare the variable hits. Note that it's not necessary to initialize variables, that is done automatically when the variable is declared if you do not do it explicitly. To be able to use the builtin function search(), which searches for the presence of a given string inside another, we put the search string in lowercase and compare it with the lowercase version of every song. The use of search() enables us to search for partial song titles as well.
When a match is found it is immediately written to standard output with the record name followed by the name of the song where the search string was found and a newline.
If there were no hits at all, the function prints out a message saying just that.
void find_song(string title)
{
string name, song;
int hits;
title=lower_case(title);
foreach(indices(records),name)
{
foreach(records[name],song)
{
if(search(lower_case(song), title) != -1)
{
write(name+"; "+song+"\n");
hits++;
}
}
}
if(!hits) write("Not found.\n");
}2.3.3 main() again
Once again main() is left unchanged, except for yet another two case statements used to call the search() and delete functions, respectively. Note that you must provide an argument to delete or it will not work properly.
case "delete":
delete_record((int)args);
break;
case "search":
find_song(args);
break;2.4 Then what?
Well that's it! The example is now a complete working example of a Pike program. But of course there are plenty of details that we haven't attended to. Error checking is for example extremely sparse in our program. This is left for you
to do as you continue to read this book. The complete listing of this example can be found in appendix B "Register program". Read it, study it and enjoy!
|
One of the case statements in the above example differs in that it is
a range. In this case, any value between constant3 and
constant4 will cause Pike to jump to expressions3. Note
that the ranges are inclusive, so the values constant3 and
constant4 are also valid.
3.1.1 if
The simplest one is called the if statement. It can be written anywhere
where a statement is expected and it looks like this:
if( expression )
statement1;
else
statement2;
Please note that there is no semicolon after the parenthesis or after the
else. Step by step, if does the following:
This is actually more or less how the interpreter executes the if statement.
In short, statement1 is executed if expression is true
otherwise statement2 is executed. If you are not interested in
having something executed if the expression is false you can drop the
whole else part like this:
if( expression )
If on the other hand you are not interested in evaluating something if the
expression is false you should use the not operator to negate
the true/false value of the expression. See chapter 5 for more information
about the not operator. It would look like this:
statement1;if( ! expression )
Any of the statements here and in the rest of this chapter can
also be a block of statements. A block is a list of statements,
separated by semicolons and enclosed by brackets. Note that you should
never put a semicolon after a block of statements. The example above
would look like this;
statement2 ;if ( ! expression )
{
statement;
statement;
statement;
}3.1.2 Switch
A more sophisticated condition control structure is the switch
statement.
A switch lets you select one of many choices depending on the value of an
expression and it can look something like this:
switch ( expression )
As you can see, a switch statement is a bit more complicated than an
if statement. It is still fairly simple however. It starts by evaluating
the expression it then searches all the case statements in the
following block. If one is found to be equal to the value returned by
the expression, Pike will continue executing the code directly following
that case statement. When a break is encountered Pike
will skip the rest of the code in the switch block and continue executing
after the block. Note that it is not strictly necessary to have a break
before the next case statement. If there is no break before the next case
statement Pike will simply continue executing and execute the code after
that case statement as well.
{
case constant1:
expressions1;
break;
case constant2:
expressions2;
break;
case constant3 .. constant4:
expressions3;
break;
default:
expressions5;
}
while ( expression )The difference in how it works isn't that big either, the statement is executed if the expression is true. Then the expression is evaluated again, and if it is true the statement is executed again. Then it evaluates the expression again and so forth... Here is an example of how it could be used:
statement;
int e=1;This would call show_record with the values 1, 2, 3 and 4.
while(e<5)
{
show_record(e);
e=e+1;
}
for ( initializer_statement ; expression ; incrementor_expression )For does the following steps:
statement ;
for(int e=1; e<5; e=e+1)
show_record(e);
doAs usual, the statement can also be a block of statements, and then you do not need a semicolon after it. To clarify, this statement executes statement first, and then evaluates the expression. If the expression is true it executes the loop again. For instance, if you want to make a program that lets your modem dial your Internet provider, it could look something like this:
statement;
while ( expression );
do {This example assumes you have written something that can communicate with the modem by using the functions write and gets.
modem->write("ATDT441-9109\n");// Dial 441-9109
} while(modem->gets()[..6]] != "CONNECT");
foreach ( array_expression, variable )We have already seen an example of foreach in the find_song function in chapter 2. What foreach does is:
statement ;
array tmp1= array_expression;
for ( tmp2 = 0; tmp2 < sizeof(tmp1); tmp2++ )
{
variable = tmp1 [ tmp2 ];
statement;
}
while(1)
{
string command=readline("> ");
if(command=="quit") break;
do_command(command);
}
while(1)This way, do_command will never be called with an empty string as argument.
{
string command=readline("> ");
if(strlen(command) == 0) continue;
if(command=="quit") break;
do_command(command);
}
#!/usr/local/bin/pikeThis would return the error code 1 to the system when the program is run.
int main()
{
return 1;
}
|
Integers are coded in 2-complement and overflows are silently ignored
by Pike. This means that if your integers are 32-bit and you add 1 to
the number 2147483647 you get the number -2147483648. This works exactly
as in C or C++.
All the arithmetic, bitwise and comparison operators can be used on integers.
Also note these functions:
All the arithmetic and comparison operators can be used on floats.
Also, these functions operates on floats:
Although a string is an array, you can not change the individual characters in the string. Instead you have to construct a new string, here is an example
of how:
All the comparison operators plus the operators listed here can be used on strings:
Also, these functions operates on strings:
4.1 Basic types
The basic types are int, float and string.
For you who are accustomed to C or C++, it may seem odd that a string
is a basic type as opposed to an array of char, but it is surprisingly
easy to get used to.
4.1.1 int
Int is short for integer, or integer number. They are normally
32 bit integers, which means that they are in the range -2147483648 to
2147483647. Note that on some machines an int might be larger
than 32 bits. Since they are integers, no decimals are allowed. An integer
constant can be written in several ways:
78 // decimal number
0116 // octal number
0x4e // hexadecimal number
'N' // Ascii character
All of the above represent the number 78. Octal notation means that
each digit is worth 8 times as much as the one after. Hexadecimal notation
means that each digit is worth 16 times as much as the one after.
Hexadecimal notation uses the letters a, b, c, d, e and f to represent the
numbers 10, 11, 12, 13, 14 and 15. The ASCII notation gives the ASCII
value of the character between the single quotes. In this case the character
is N which just happen to be 78 in ASCII.
4.1.2 float
Although most programs only use integers, they are unpractical when doing
trigonometric calculations, transformations or anything else where you
need decimals. For this purpose you use float. Floats are normally
32 bit floating point numbers, which means that they can represent very large
and very small numbers, but only with 9 accurate digits. To write a floating
point constant, you just put in the decimals or write it in the exponential
form:
3.14159265358979323846264338327950288419716939937510
Of course you do not need this many decimals, but it doesn't hurt either.
Usually digits after the ninth digit are ignored, but on some architectures
float might have higher accuracy than that. In the exponential form,
e means "times 10 to the power of", so 1.0e9 is equal to
"1.0 times 10 to the power of 9".
1.0e9
1.0e-9
4.1.3 string
A string can be seen as an array of values from 0 to 255.
Usually a string contains text such as a word, a sentence, a page or
even a whole book. But it can also contain parts of a binary file,
compressed data or other binary data. Strings in Pike are shared,
which means that identical strings share the same memory space. This
reduces memory usage very much for most applications and also speeds
up string comparisons. We have already seen how to write a constant
string:
"hello world" // hello world
"he" "llo" // hello
"\116" // N (116 is the octal ASCII value for N)
"\t" // A tab character
"\n" // A newline character
"\r" // A carriage return character
"\b" // A backspace character
"\0" // A null character
"\"" // A double quote character
"\\" // A singe backslash
"hello world\116\t\n\r\b\0\"\\" // All of the above
As you can see, any sequence of characters within double quotes is a string.
The backslash character is used to escape characters that are not allowed or
impossible to type. As you can see, \t is the sequence to produce
a tab character, \\ is used when you want one backslash and
\" is used when you want a double quote to be a part of the string
instead of ending it. Also, \XXX where XXX is an
octal number from 000 to 377 lets you write any character you want in the
string, even null characters. If you write two constant strings after each
other, they will be concatenated into one string.
string s = "hello torld";
s=s[..5]+"w"+s[7..];
({ }) // Empty array
({ 1 }) // Array containing one element of type int
({ "" }) // Array containing a string
({ "", 1, 3.0 }) // Array of three elements, each of different type
As you can see, each element in the array can contain any type of value.
Indexing and ranges on arrays works just like on strings, except with
arrays you can change values inside the array with the index operator.
However, there is no way to change the size of the array, so if you want
to append values to the end you still have to add it to another array
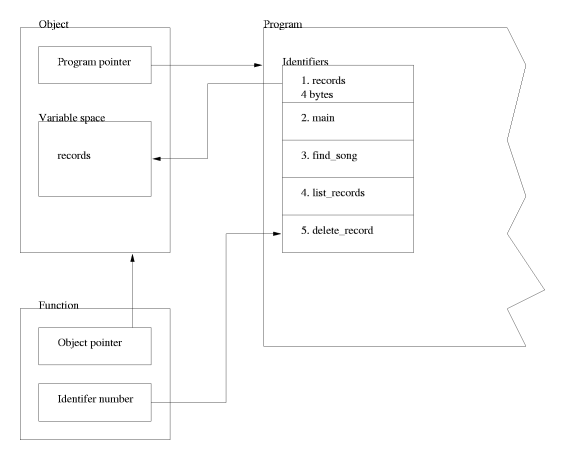
which creates a new array. Figure 4.1 shows how the schematics of an array.
As you can see, it is a very simple memory structure.

Operators and functions usable with arrays:

Each index-value pair is floating around freely inside the mapping. There is exactly one value for each index. We also have a (magical) lookup function. This lookup function can find any index in the mapping very quickly. Now, if the mapping is called m and we index it like this: m [ i ] the lookup function will quickly find the index i in the mapping and return the corresponding value. If the index is not found, zero is returned instead. If we on the other hand assign an index in the mapping the value will instead be overwritten with the new value. If the index is not found when assigning, a new index-value pair will be added to the mapping. Writing a constant mapping is easy:
([ ]) // Empty mapping
([ 1:2 ]) // Mapping with one index-value pair, the 1 is the index
([ "one":1, "two":2 ]) // Mapping which maps words to numbers
([ 1:({2.0}), "":([]), ]) // Mapping with lots of different types
As with arrays, mappings can contain any type. The main difference is that the index can be any type too. Also note that the index-value pairs in a mapping are not stored in a specific order. You can not refer to the fourteenth key-index pair, since there is no way of telling which one is the fourteenth. Because of this, you cannot use the range operator on mappings.
The following operators and functions are important to use mappings:

Instead, the index operator will return 1 if the value was found in the multiset and 0 if it was not. When assigning an index to a multiset like this: mset[ ind ] = val the index ind will be added to the multiset mset if val is true. Otherwise ind will be removed from the multiset instead.
Writing a constant multiset is similar to writing an array:
(< >) // Empty multiset (< 17 >) // Multiset with one index: 17 (< "", 1, 3.0, 1 >) // Multiset with 3 indexesNote that you can actually have two of the same index in a multiset. This is normally not used, but can be practical at times.
program p = compile_file("hello_world.pike");You can also use the cast operator like this:
program p = (program) "hello_world";This will also load the program hello_world.pike, the only difference is that it will cache the result so that next time you do (program)"hello_world" you will receive the _same_ program. If you call compile_file("hello_world.pike") repeatedly you will get a new program for each time.
There is also a way to write programs inside programs with the help of the class keyword:
class class_name {
inherits, variables and functions
}
The class keyword can be written as a separate entity
outside of all functions, but it is also an expression which returns the
program written between the brackets. The class_name is
optional. If used you can later refer to that program by the name
class_name.
This is very similar to how classes are written in C++ and can be used
in much the same way. It can also be used to create structs
(or records if you program Pascal).
Let's look at an example:
class record {This could be a small part of a better record register program. It is not a complete executable program in itself. In this example we create a program called record which has three identifiers. In add_empty_record a new object is created by calling record. This is called cloning and it allocates space to store the variables defined in the class record. Show_record takes one of the records created in add_empty_record and shows the contents of it. As you can see, the arrow operator is used to access the data allocated in add_empty_record. If you do not understand this section I suggest you go on and read the next section about objects and then come back and read this section again.
string title;
string artist;
array(string) songs;
}
array(object(record)) records = ({});
void add_empty_record()
{
records+=({ record() });
}
void show_record(object(record) rec)
{
write("Record name: "+rec->title+"\n");
write("Artist: "+rec->artist+"\n");
write("Songs:\n");
foreach(rec->songs, string song)
write(" "+song+"\n");
}
program compile_file(string filename);Compile_file simply reads the file given as argument, compiles it and returns the resulting program. Compile_string instead compiles whatever is in the string p. The second argument, filename, is only used in debug printouts when an error occurs in the newly made program.
program compile_string(string p, string filename);

class record {Here we can clearly see how the function show prints the contents of the variables in that object. In essence, instead of accessing the data in the object with the -> operator, we call a function in the object and have it write the information itself. This type of programming is very flexible, since we can later change how record stores its data, but we do not have to change anything outside of the record program.
string title;
string artist;
array(string) songs;
void show()
{
write("Record name: "+title+"\n");
write("Artist: "+artist+"\n");
write("Songs:\n");
foreach(songs, string song)
write(" "+song+"\n");
}
}
array(object(record)) records = ({});
void add_empty_record()
{
records+=({ record() });
}
void show_record(object rec)
{
rec->show();
}
Functions and operators relevant to objects:
int foo() { return 1; }In this example, the function bar returns a pointer to the function foo. No indexing is necessary since the function foo is located in the same object. The function gazonk simply calls foo. However, note that the word foo in that function is an expression returning a function pointer that is then called. To further illustrate this, foo has been replaced by bar() in the function teleledningsanka.
function bar() { return foo; }
int gazonk() { return foo(); }
int teleledningsanka() { return bar()(); }
For convenience, there is also a simple way to write a function inside another function. To do this you use the lambda keyword. The syntax is the same as for a normal function, except you write lambda instead of the function name:
lambda ( types ) { statements }The major difference is that this is an expression that can be used inside other function. Example:
function bar() { return lambda() { return 1; }; )This is the same as the first two lines in the previous example, the keyword lambda allows you to write the function inside bar.
Note that unlike C++ and Java you can not use function overloading in Pike. This means that you cannot have one function called 'foo' which takes an integer argument and another function 'foo' which takes a float argument.
This is what you can do with a function pointer.
int main(int argc, array(string) argv)This program will of course write Hello world.
{
array(string) tmp;
tmp=argv;
argv[0]="Hello world.\n";
write(tmp[0]);
}
Sometimes you want to create a copy of a mapping, array or object. To do so you simply call copy_value with whatever you want to copy as argument. Copy_value is recursive, which means that if you have an array containing arrays, copies will be made of all those arrays.
If you don't want to copy recursively, or you know you don't have to copy recursively, you can use the plus operator instead. For instance, to create a copy of an array you simply add an empty array to it, like this: copy_of_arr = arr + ({}); If you need to copy a mapping you use an empty mapping, and for a multiset you use an empty multiset.
int x; // x is an integer int|string x; // x is a string or an integer array(string) x; // x is an array of strings array x; // x is an array of mixed mixed x; // x can be any type string *x; // x is an array of strings // x is a mapping mapping from int to string mapping(string:int) x; // x is a clone of Stdio.File object(Stdio.File) x; // x is a function that takes two integer // arguments and returns a string function(int,int:string) x; // x is a function taking any amount of // integer arguments and returns nothing. function(int...:void) x; // x is ... complicated mapping(string:function(string|int...:mapping(string:string*))) x;As you can see there are some interesting ways to specify types. Here is a list of what is possible:
| Function | Syntax | Identifier | Returns |
|---|---|---|---|
| Addition | a + b | `+ | the sum of a and b |
| Subtraction | a - b | `- | b subtracted from a |
| Negation | - a | `- | minus a |
| Multiplication | a * b | `* | a multiplied by b |
| Division | a / b | `/ | a divided by b |
| Modulo | a % b | `% | the remainder of a division between a and b |
The third column, "Identifier" is the name of the function that actually evaluates the operation. For instance, a + b can also be written as `+(a, b). I will show you how useful this can be at the end of this chapter.
When applied to integers or floats these operators do exactly what they are supposed to do. The only operator in the list not known from basic math is the modulo operator. The modulo operator returns the rest of an integer division. It is the same as calculating a - floor(a / b) * b. floor rounds the value down to closest lower integer value. Note that the call to floor isn't needed when operating on integers, since dividing two integers will return the result as an integer and it is always rounded down. For instance, 8 / 3 would return 2.
If all arguments to the operator are integers, the result will also be an integer. If one is a float and the other is an integer, the result will be a float. If both arguments are float, the result will of course be a float.
However, there are more types in Pike than integers and floats. Here is the complete list of combinations of types you can use with these operators:
| Operation | Returned type | Returned value |
|---|---|---|
| int + int | int | the sum of the two values |
| float + int int + float float + float | float | the sum of the two values |
| string + string int + string float + string string + int string + float | string | In this case, any int or float is first converted to a string. Then the two strings are concatenated and the resulting string is returned. |
| array + array | array | The two arrays are concatenated into a new array and that new array is returned. |
| mapping + mapping | mapping | A mapping with all the index-value pairs from both mappings is returned. If an index is present in both mappings the index-value pair from the right mapping will be used. |
| multiset + multiset | multiset | A multiset with all the indices from both muiltisets is returned. |
| int - int | int | The right value subtracted from the left. |
| float - int int - float float - float | float | The right value subtracted from the left. |
| string - string | string | A copy of the left string with all occurrences of the right string removed. |
| array - array | array | A copy of the right array with all elements present in the right array removed. Example: ({2,1,4,5,3,6,7}) - ({3,5,1}) will return ({2,4,6,7}). |
| mapping - mapping | mapping | A new mapping with all index-value pairs from the left mapping, except those indexes that are also present in the right mapping. |
| multiset - multiset | multiset | A copy of the left multiset without any index present in the left multiset. |
| - int | int | Same as 0 - int. |
| - float | float | Same as 0 - float. |
| int * int | int | the product of the two values |
| float * int int * float float * float | float | the product of the two values |
| array(string) * string | string | All the strings in the array are concatenated with the string on the right in between each string. Example: ({"foo,"bar})*"-" will return "foo-bar". |
| int / int | int | The right integer divided by the left integer rounded towards minus infinity. |
| float / int int / float float / float | float | The right value divided by the left value. |
| string / string | array(string) | In symmetry with the multiplication operator, the division operator can split a string into pieces. The right string will be split at every occurrence of the right string and an array containing the results will be returned. Example: "foo-bar"/"-" will return ({"foo","bar"}) |
| int % int | int | The rest of a division. If a and b are integers, a%b is the same as a-(a/b)*b |
|
float % float int % float float % int | float | The rest of a division. If a and b are floats, a%b is the same as a-floor(a/b)*b |
| Function | Syntax | Identifier | Returns |
|---|---|---|---|
| Same | a == b | `== | 1 if a is the same value as b, 0 otherwise |
| Not same | a != b | `!= | 0 if a is the same value as b, 1 otherwise |
| Greater than | a > b | `> | 1 if a is greater than b, 0 otherwise |
| Greater than or equal to | a >= b | `>= | 1 if a is greater to or equal to b, 0 otherwise |
| Lesser than | a < b | `< | 1 if a is lesser than b, 0 otherwise |
| Lesser than or equal to | a <= b | `<= | 1 if a is lesser than or equal to b, 0 otherwise |
The other operators in the table above can only be used with integers, floats and strings. If you compare an integer with a float, the int will be promoted to a float before the comparison. When comparing strings, lexical order is used and the value of the environment variables LC_CTYPE and LC_LANG is respected.
| Function | Syntax | Returns |
|---|---|---|
| And | a && b | If a is false, a is returned and b is not evaluated. Otherwise, b is returned. |
| Or | a || b | If a is true, a is returned and b is not evaluated. Otherwise, b is returned. |
| Not | ! a | Returns 0 if a is true, 1 otherwise. |
| If-else | a ? b : c | If a is true, b is returned and c is not evaluated. Otherwise c is returned and b is not evaluated. |
| Function | Syntax | Identifier | Returns |
|---|---|---|---|
| Shift left | a << b | `<< | Multiplies a by 2 b times. |
| Shift right | a >> b | `>> | Divides a by 2 b times. |
| Inverse (not) | ~ a | `~ | Returns -1-a. |
| Intersection (and) | a & b | `& | All elements present in both a and b. |
| Union (or) | a | b | `| | All elements present in a or b. |
| Symmetric difference (xor) | a ^ b | `^ | All elements present in a or b, but not present in both. |
When intersection, union or symmetric difference is used on an array each element in the array is considered by itself. So intersecting two arrays will result in an array with all elements that are present in both arrays. Example: ({7,6,4,3,2,1}) & ({1, 23, 5, 4, 7}) will return ({7,4,1}). The order of the elements in the returned array will always be taken from the left array. Elements in multisets are treated the same as elements in arrays. When doing a set operator on a mapping however, only the indices are considered. The values are just copied with the indexes. If a particular index is present in both the right and left argument to a set operator, the one from the right side will be used. Example: ([1:2]) | ([1:3]) will return ([1:3]).
| Function | Syntax | Identifier | Returns |
|---|---|---|---|
| Index | a [ b ] | `[] | Returns the index b from a. |
| Lookup | a ->identifier | `-> | Looks up the identifier. Same as a["identifier"]. |
| Assign index | a [ b ] = c | `[]=; | Sets the index b in a to c. |
| Assign index | a ->identifier = c | `->= | Sets the index "identifier" in a to c. |
| Range | a [ b .. c] | `[..] | Returns a slice of a starting at the index b and ending at c. |
| Range | a [ .. c] | `[..] | Returns a slice of a starting at the beginning of a and ending at c. |
| Range | a [ b .. ] | `[..] | Returns a slice of a from the index b to the end of a. |
| Operation | Returns |
|---|---|
| string[int] | Returns the ascii value of the Nth character in the string. |
| array[int] | Return the element in the array corresponding to the integer. |
| array[int]=mixed | Sets the element in the array to the mixed value. |
|
multiset[mixed] multiset->identifier | Returns 1 if the index (the value between the brackets) is present in the multiset, 0 otherwise. |
|
multiset[mixed]=mixed multiset->identifier=mixed | If the mixed value is true the index is added to the multiset. Otherwise the index is removed from the multiset. |
|
mapping[mixed] mapping->identifier | Returns the value associated with the index, 0 if it is not found. |
|
mapping[mixed]=mixed mapping->identifier=mixed | Associate the second mixed value with the first mixed value. |
|
object[string] object->identifier | Returns the value of the named identifier in the object. |
|
object[string]=mixed object->identifier=mixed | Set the given identifier in the object to the mixed value. Only works if the identifier references a variable in the object. |
| string[int..int] | Returns a piece of the string. |
| array[int..int] | Returns a slice of the array. |
When indexing an array or string it is sometimes convenient to access index from the end instead of from the beginning. This function can be performed by using a negative index. Thus arr[-i] is the same as arr[sizeof(arr)-i]. Note however that this behavior does not apply to the range operator. Instead the range operator clamps it's arguments to a suitable range. This means that a[b..c] will be treated as follows:
variable = expression;The variable can be a local variable, a global variable or an index in an array, object, multiset or mapping. This will of course set the value stored in variable to expression. Note that the above is also an expression which returns the value of the expression. This can be used in some interesting ways:
variable1 = variable2 = 1;Using assignments like this can however be confusing to novice users, or users who come from a Pascal or Basic background. Especially the if statement can be mistaken for if(variable == expression) which would mean something completely different. As I mentioned earlier, the assignment operator can be combined with another operator to form operators that modify the contents of a variable instead of just assigning it. Here is a list of all the combinations:// Assign 1 to both variables
variable1 =(variable2 = 1);// Same as above // Write the value of the expression, if any
if(variable = expression)
write(variable);
| Syntax | Same as | Function |
|---|---|---|
| variable += expression | variable = variable + expression | Add expression to variable |
| variable -= expression | variable = variable - expression | Subtract expression from variable |
| variable *= expression | variable = variable * expression | Multiply variable with expression |
| variable /= expression | variable = variable / expression | Divide variable by expression |
| variable %= expression | variable = variable % expression | Modulo variable by expression |
| variable <<= expression | variable = variable << expression | Shift variable expression bits left |
| variable >>= expression | variable = variable >> expression | Shift variable expression bits right |
| variable |= expression | variable = variable | expression | Or variable with expression |
| variable &= expression | variable = variable & expression | And variable with expression |
| variable ^= expression | variable = variable ^ expression | Xor variable with expression |
In all of the above expression variable can also be an index in an array, mapping or multiset.
| Function | Syntax | Identifier | Returns |
|---|---|---|---|
| Calling | a ( arguments ) | `() | Calls the function a. |
| splice | @ a | none | Sends each element in the array a as an individual argument to a function call. |
| Increment | ++ a | none | Increments a and returns the new value for a. |
| Decrement | -- a | none | Decrements a and returns the new value for a. |
| Post increment | a ++ | none | Increments a and returns the old value for a. |
| Post decrement | a -- | none | Decrements a and returns the old value for a. |
| casting | (type) a | none | Tries to convert a into a value of the specified type. |
| Null | a, b | none | Evaluates a and b, then returns b. |
object clone(mixed p, mixed ... args) { ( (program)p )(@args); }
On the subject of function calls, the splice operator should also be mentioned. The splice operator is an at sign in front of an expression. The expression should always be an array. The splice operator sends each of the elements in the array as a separate argument to the function call. The splice operator can only be used in an argument list for a function call.
Then there are the increment and decrement operators. The increment and decrement operators are somewhat limited: they can only be used on integers. They provide a short and fast way to add or subtract one to an integer. If the operator is written before the variable (++a) the returned value will be what the variable is after the operator has added/subtracted one to it. If the operator is after the variable (a++) it will instead return the value of the variable before it was incremented/decremented.
Casting is used to convert one type to another, not all casts are possible. Here is a list of all casts that actually _do_ anything:
| casting from | to | operation |
|---|---|---|
| int | string | Convert the int to ASCII representation |
| float | string | Convert the float to ASCII representation |
| string | int | Convert decimal, octal or hexadecimal number to an int. |
| string | float | Convert ASCII number to a float. |
| string | program | String is a filename, compile the file and return the program. Results are cached. |
| string | object | This first casts the string to a program, (see above) and then clones the result. Results are cached. |
You can also use the cast operator to tell the compiler things. If a is a variable of type mixed containing an int, then the expression (int)a can be used instead of a and that will tell the compiler that the type of that expression is int.
Last, and in some respect least, is the comma operator. It doesn't do much. In fact, it simply evaluates the two arguments and then returns the right hand one. This operator is mostly useful to produce smaller code, or to make defines that can be used in expressions.
| Operators |
|---|
Examples:
| The expression | is evaluated in this order: |
|---|---|
| 1+2*2 | 1+(2*2) |
| 1+2*2*4 | 1+((2*2)*4) |
| (1+2)*2*4 | ((1+2)*2)*4 |
| 1+4,c=2|3+5 | (1+4),(c=(2|3)+5) |
| 1+5 & 4 == 3 | (1+(5 & 4)) == 3 |
| c=1,99 | (c=1),99 |
| !a++ + ~--a() | (!(a++)) + (~((--a)())) |
This analogy has one major flaw, when running programs in UNIX they actually run simultaneously. UNIX is multitasking, Pike is not. When one object is executing code, all the other objects has to wait until they are called. An exception is if you are using threads as will be discussed in a later chapter.
In my experience, the advantages of object oriented programming are:
program scriptclass=compile_file(argv[0]); // Load script object script=scriptclass(); // clone script int ret=script->main(sizeof(argv), argv); // call main()Similarly, if you want to load another file and call functions in it, you can do it with compile_file(), or you can use the cast operator and cast the filename to a string. You can also use the module system, which we will discuss further in the next chapter.
If you don't want to put each program in a separate file, you can use the class keyword to write all your classes in one file. We have already seen an example how this in chapter 4, but let's go over it in more detail. The syntax looks like this:
class class_name {This construction can be used almost anywhere within a normal program. It can be used outside all functions, but it can also be used as an expression in which case the defined class will be returned. In this case you may also leave out the class_name and leave the class unnamed. The class definition is simply the functions and programs you want to add to the class. It is important to know that although the class is defined in the same file as other classes and functions it can not immediately access data in its surroundings. Only constants defined before the class in the same file can be used. Example:
class_definition
}
constant x = 17;This works because x is a constant. If x had been a variable or function it would not have worked. In future versions of Pike it may be possible to do this with variables as well. To make it easier to program, defining a class is also to define a constant with that name. Essentially, these two lines of code do the same thing:
class foobar {
int test() { return x; }
};
class foo {};Because classes defined as constants, it is possible to use a class defined inside classes you define later, like this:
constant foo = class {};
class foo
{
int test() { return 17; }
};
class bar
{
program test2() { return foo; }
};
inherit "hello_world";What inherit does is that it copies all the variables and functions from the inherited program into the current one. You can then re-define any function or variable you want, and you can call the original one by using a :: in front of the function name. The argument to inherit can be one of the following:
int main(int argc, array(string) argv)
{
write("Hello world version 1.0\n");
return ::main(argc,argv);
}
Let's look at an example. We'll split up an earlier example into three parts and let each inherit the previous part. It would look something like this:

inherit Stdio.File;As you can see it would be impossible to separate the different read and main functions without using inherit names. If you tried calling just read without any :: or inherit name in front of it Pike will call the last read defined, in this case it will call read in the fourth inherit.// This inherit is named File
inherit Stdio.FILE;// This inherit is named FILE
inherit "hello_word";// This inherit is named hello_world
inherit Stdio.File : test1;// This inherit is named test1
inherit "hello_world" : test2;// This inherit is named test2
void test()
{
File::read();// Read data from the first inherit
FILE::read();// Read data from the second inherit
hello_world::main(0,({}));// Call main in third inherit
test1::read();// Read data from fourth inherit
test2::main(0,({}));// Call main in fourth inherit
::read();// Read data from all inherits
}
If you leave the inherit name blank and just call ::read Pike will call all inherited read() functions. If there is more than one inherited read function the results will be returned in an array.
Let's look at another example:
#!/usr/local/bin/pikeThis short piece of code works a lot like the UNIX command cat. It reads all the files given on the command line and writes them to stdout. As an example, I have inherited Stdio.File twice to show you that both files are usable from my program.
inherit Stdio.File : input;
inherit Stdio.File : output;
int main(int argc, array(string) argv)
{
output::create("stdout");
for(int e=1;e<sizeof(argv);e++)
{
input::open(argv[e],"r");
while(output::write(input::read(4096)) == 4096);
}
}
The following table assumes that a and b are objects and shows what will be evaluated if you use that particular operation on an object. Note that some of these operators, notably == and ! have default behavior which will be used if the corresponding method is not defined in the object. Other operators will simply fail if called with objects. Refer to chapter 5 "Operators" for information on which operators can operate on objects without operator overloading.
| Operation | Will call |
|---|---|
| a+b | a->`+(b) |
| a+b+c+d | a->`+(b,c,d) |
| a-b | a->`-(b) |
| a&b | a->`&(b) |
| a|b | a->`|(b) |
| a^b | a->`^(b) |
| a>>b | a->`>>(b) |
| a<<b | a->`<<(b) |
| a*b | a->`*(b) |
| a*b*c*d | a->`*(b,c,d) |
| a/b | a->`/(b) |
| a%b | a->`%(b) |
| ~a | a->`~() |
| a==b | a->`==(b) or b->`==(a) |
| a!=b | !( a->`==(b) ) or !( b->`==(a) ) |
| a<b | a->`<(b) |
| a>b | a->`>(b) |
| a<=b | !( b->`>(a) ) |
| a>=b | !( b->`<(a) ) |
| (int)a | a->cast("int") |
| !a | a->`!() |
| if(a) { ... } | !( a->`!() ) |
| a[b] | a->`[](b) |
| a[b]=c | a->`[]=(b,c) |
| a->foo | a->`->("foo") |
| a->foo=b | a->`->=("foo",b) |
| sizeof(a) | a->_sizeof() |
| indices(a) | a->_indices() |
| values(a) | a->_values() |
| a(b) | a->`()(b) |
Here is a really silly example of a program that will write 10 to stdout when executed.
#!/usr/local/bin/pikeIt is important to know that some optimizations are still performed even when operator overloading is in effect. If you define a multiplication operator and multiply your object with one, you should not be surprised if the multiplication operator is never called. This might not always be what you expect, in which case you are better off not using operator overloading.
class three {
int `+(int foo) { return 3+foo; }
};
int main()
{
write(sprintf("%d\n",three()+7));
}
|
int sscanf(string str, string fmt, lvalue ...)The string str will be matched against the format string fmt. fmt can contain strings separated by %d,%s,%c and %f. Every % corresponds to one lvalue. An lvalue is the name of a variable, a name of a local variable, an index in an array, mapping or object. It is because of these lvalues that sscanf can not be implemented as a normal function.
Whenever a percent is found in the format string, a match is according to the following table:
| %d | reads an integer |
| %o | reads an octal integer |
| %x | reads a hexadecimal integer |
| %D | reads an integer that is either octal (leading zero), hexadecimal (leading 0x) or decimal. |
| %f | reads a float |
| %c | matches one char and returns it as an integer |
| %2c | matches two chars and returns them as an integer (short) |
| %s | reads a string. If followed by %d, %s will read any non-numerical characters. If followed by a %[], %s will read any characters not present in the set. If followed by normal text, %s will match all characters up to but not including the first occurrence of that text. |
| %5s | gives a string of 5 characters (5 can be any number) |
| %[set] | matches a string containing a given set of characters (those given inside the brackets). %[^set] means any character except those inside brackets. Example: %[0-9H] means any number or 'H'. |
If a * is put between the percent and the operator, the operator will only match its argument, not assign any variables.
Sscanf does not use backtracking. Sscanf simply looks at the format string up to the next % and tries to match that with the string. It then proceeds to look at the next part. If a part does not match, sscanf immediately returns how many % were matched. If this happens, the lvalues for % that were not matched will not be changed.
Let's look at a couple of examples:
// a will be assigned "oo" and 1 will be returned
sscanf("foo","f%s",a);// a will be 4711 and b will be "bar", 2 will be returned
sscanf("4711bar","%d%s",a,b);// a will become "test"
sscanf(" \t test","%*[ \t]%s",a)// Remove "the " from the beginning of a string // If 'str' does not begin with "the " it will not be changed
sscanf(str,"the %s",str);
SEE ALSO : sprintf
7.2 catch & throw
Catch is used to trap errors and other exceptions in Pike.
It works by making a block of code into an expression, like this:
catch { statements }
If an error occurs, catch will return a description of the error.
The description of the error has the following format:
({
If no error occurs, catch will return zero. You may emulate your own errors
using the function throw, described in chapter 15 "All the builtin functions".
"error description",
backtrace()
})
Example:
int x,y;// This might generate "division by zero"
mixed error=catch { x/=y; };
gauge { statements }However, gauge simply returns how many milliseconds the code took to execute. This can be used to find out how fast your code actually is.. :) Only CPU time used by the Pike process is measured. This means that if it takes two seconds to execute but only uses 50% CPU, this function will return 1000.
typeof( exit(1) )This will return the string "void" since exit is a function that returns void. It will not execute the function exit and exit the process as you might expect.
here is a list of the basic Pike modules:
* These modules might not be available depending on how Pike was compiled
and whether support for these functions exist on your system.
When you use Stdio Pike will look for that module:
8.1 How to use modules
A module is a bunch of functions, programs or other modules collected in
one symbol. For instance, the module Stdio contains the objects
stdin, stdout and stderr. To access these objects
you can write Stdio.stdin, Stdio.stdout or
Stdio.stderr anywhere in your program where an object of that type
is acceptable. If you use Stdio a lot you can use put
import Stdio; in the beginning of your program. This will import
all the identifiers from the module Stdio into your program, making it
possible to write just stdin instead of Stdio.stdin.
8.2 Where do modules come from?
Modules are not loaded until you use them, which saves memory unless you use
all the modules. However, if you want to write your own modules it is important
to know how modules are located and loaded.
For each of these directories, Pike will do the following:
As you can see, quite a lot of work goes into finding the modules, this
makes it possible to choose the most convenient way to build your own Pike
modules.
8.3 The . operator
The period operator is not really an operator, as it is always evaluated
during the compilation. It works similarly to the index and arrow operators,
but can only be used on constant values such as modules. In most cases,
modules are simply a clone of a program, in which case the identifiers in
the module will be the same as those in the program. But some modules,
like those created from directories, overload the index operator so that
the identifiers in the module can be something other than those in the program.
For directory modules, the index operator looks in the directory it was
cloned for to find the identifiers.
8.4 How to write a module
Here is an example of a simple module:
constant PI = 3.14159265358979323846264338327950288419716939937510;
if we save this short file as Trig.pike.pmod we can now use this
module like this:
float cos2(float f) { return pow(cos(f),2.0); }int main()
or like this:
{
write(sprintf("%f\n",Trig.cos2(Trig.PI));
}import Trig;
int main()
{
write(sprintf("%f\n",cos2(PI));
}8.5 Simple exercises
|
However, instead of cloning and then calling open(), you can clone the File with a filename and open mode. This is the same thing as cloning and then calling open, except shorter and faster.
Alternatively, you can clone a File with "stdin", "stdout" or "stderr" as argument. This will open the specified standard stream.
| 'r' | open file for reading |
| 'w' | open file for writing |
| 'a' | open file for append (use with 'w') |
| 't' | truncate file at open (use with 'w') |
| 'c' | create file if it doesn't exist (use with 'w') |
| 'x' | fail if file already exist (use with 'c') |
How should _always_ contain at least one of 'r' or 'w'.
Returns 1 on success, 0 otherwise.
If a one is given as second argument to read(), read will not try its best to read as many bytes as you asked it to read, it will merely try to read as many bytes as the system read function will return. This mainly useful with stream devices which can return exactly one row or packet at a time.
If no arguments are given, read will read to the end of the file/stream.
If no arguments are given, the callbacks are not changed. The stream is just set to nonblocking mode.
/* Redirect stdin to come from the file 'foo' */
object o=Stdio.File();
o->open("foo","r");
o->dup2(Stdio.File("stdin"));
If you give a port number to this function, the socket will be bound to this port locally before connecting anywhere. This is only useful for some silly protocols like FTP. You may also specify an address to bind to if your machine has many IP numbers.
This function returns 1 for success, 0 otherwise. Note that if the socket is in nonblocking mode, you have to wait for a write or close callback before you know if the connection failed or not.
Here is an example of how to use the TCP functions in Stdio.File in blocking mode. This short program takes a URL as first argument, connects to the WWW server, sends a HEAD request and writes the reply to stdout. For clarity, all calls to Stdio.File use File:: even if that is not strictly necessary.
import Stdio;
inherit File;
int main(int argc, array(string) argv)
{
string host;
string path="";
int port=80;
sscanf(argv[1],"http://%s",argv[1]);
sscanf(argv[1],"%s/%s",host,path);
sscanf(host,"%s:%d",host,port);
if(!File::open_socket())
{
perror("Open socket failed");
exit(1);
}
if(!File::connect(host,port))
{
perror("Failed to connect to remote host");
exit(1);
}
File::write(sprintf("HEAD /%s HTTP/1.0\n",path));
stdout::write(File::read());
}
Example:
int main()This example will read lines from standard input for as long as there are more lines to read. Each line will then be written to stdout together with the line number. We could use Stdio.stdout.write instead of just write because they are the same function.
{
int line;
while(string s=Stdio.stdin.gets())
write(sprintf("%5d: %s\n",line++,s));
}
If the optional argument IP is given, bind will try to bind to this IP name (or number).
Usually WWW involves HTML. HTML (Hyper-Text Markup Language) is a way to write documents with embedded pictures and links to other pages. These links are normally displayed underlined and if you click them your WWW- browser will load whatever document that link leads to.
#!/usr/local/bin/pikeWe inherit Stdio.Port into this program so we can bind a TCP socket to accept incoming connection. A socket is simply a number to separate communications to and from different programs on the same computer./* A very small httpd capable of fetching files only. * Written by Fredrik H³binette as a demonstration of Pike. */
inherit Stdio.Port;
Next are some constants that will affect how uHTTPD will operate. This uses the preprocessor directive #define. The preprocessor is the first stage in the compiling process and can make textual processing of the code before it is compiled. As an example, after the first define below, all occurrences of 'BLOCK' will be replaced with 16060.
A port is a destination for a TCP connection. It is simply a number on the local computer. 1905 is not the standard port for HTTP connections though, which means that if you want to access this WWW server from a browser you need to specify the port like this: http://my.host.my.domain:1905//* Amount of data moved in one operation */
#define BLOCK 16060/* Where do we have the html files ? */
#define BASE "/usr/local/html/"/* File to return when we can't find the file requested */
#define NOFILE "/user/local/html/nofile.html"/* Port to open */
#define PORT 1905
Next we declare a class called output_class. Later we will clone one instance of this class for each incoming HTTP connection.
class output_classOur new class inherits Stdio.File twice. To be able to separate them they are then named 'socket' and 'file'.
{
inherit Stdio.File : socket;
inherit Stdio.File : file;
int offset=0;Then there is a global variable called offset which is initialized to zero. (Each instance of this class will have its own instance of this variable, so it is not truly global, but...) Note that the initialization is done when the class is cloned (or instantiated if you prefer C++ terminology).
Next we define the function write_callback(). Later the program will go into a 'waiting' state, until something is received to process, or until there is buffer space available to write output to. When that happens a callback will be called to do this. The write_callback() is called when there is buffer space available. In the following lines 'void' means that it does not return a value. Write callback will be used further down as a callback and will be called whenever there is room in the socket output buffer.
void write_callback()The following line means: call seek in the inherited program 'file'.
{
int written;
string data;
file::seek(offset);Move the file pointer to the where we want to the position we want to read from. The file pointer is simply a location in the file, usually it is where the last read() ended and the next will begin. seek() can move this pointer to where we want it though.
data=file::read(BLOCK);Read BLOCK (16060) bytes from the file. If there are less that that left to read only that many bytes will be returned.
if(strlen(data))If we managed to read something...
{
written=socket::write(data);... we try to write it to the socket.
if(written >= 0)Update offset if we managed to write to the socket without errors.
{
offset+=written;
return;
}
werror("Error: "+socket::errno()+".\n");If something went wrong during writing, or there was nothing left to read we destruct this instance of this class.
}
destruct(this_object());That was the end of write_callback()
}
Next we need a variable to buffer the input received in. We initialize it to an empty string.
string input="";And then we define the function that will be called when there is something in the socket input buffer. The first argument 'id' is declared as mixed, which means that it can contain any type of value. The second argument is the contents of the input buffer.
void read_callback(mixed id,string data)Append data to the string input. Then we check if we have received a a complete line yet. If so we parse this and start outputting the file.
{
string cmd;
input+=data;
if(sscanf(input,"%s %s%*[\012\015 \t]",cmd,input)>2)This sscanf is pretty complicated, but in essence it means: put the first word in 'input' in 'cmd' and the second in 'input' and return 2 if successful, 0 otherwise.
{
if(cmd!="GET")If the first word isn't GET print an error message and terminate this instance of the program. (and thus the connection)
{
werror("Only method GET is supported.\n");
destruct(this_object());
return;
}
sscanf(input,"%*[/]%s",input);Remove the leading slash.
input=BASE+combine_path("/",input);Combine the requested file with the base of the HTML tree, this gives us a full filename beginning with a slash. The HTML tree is the directory on the server in which the HTML files are located. Normally all files in this directory can be accessed by anybody by using a WWW browser. So if a user requests 'index.html' then that file name is first added to BASE (/home/hubbe/www/html/ in this case) and if that file exists it will be returned to the browser.
if(!file::open(input,"r"))Try opening the file in read-only mode. If this fails, try opening NOFILE instead. Opening the file will enable us to read it later.
{
if(!file::open(NOFILE,"r"))If this fails too. Write an error message and destruct this object.
{
werror("Couldn't find default file.\n");Ok, now we set up the socket so we can write the data back.
destruct(this_object());
return;
}
}
socket::set_buffer(65536,"w");Set the buffer size to 64 kilobytes.
socket::set_nonblocking(0,write_callback,0);Make it so that write_callback is called when it is time to write more data to the socket.
write_callback();Jump-start the writing.
}That was the end of read_callback().
}
This function is called if the connection is closed while we are reading from the socket.
void selfdestruct() { destruct(this_object()); }This function is called when the program is instantiated. It is used to set up data the way we want it. Extra arguments to clone() will be sent to this function. In this case it is the object representing the new connection.
void create(object f)We insert the data from the file f into 'socket'.
{
socket::assign(f);
socket::set_nonblocking(read_callback,0,selfdestruct);Then we set up the callback functions and sets the file nonblocking. Nonblocking mode means that read() and write() will rather return that wait for I/O to finish. Then we sit back and wait for read_callback to be called.
}End of create()
};End of the new class.
Next we define the function called when someone connects.
void accept_callback()This creates a local variable of type 'object'. An object variable can contain a clone of any program. Pike does not consider clones of different programs different types. This also means that function calls to objects have to be resolved at run time.
{
object tmp_output;
tmp_output=accept();The function accept clones a Stdio.File and makes this equal to the newly connected socket.
if(!tmp_output) return;If it failed we just return.
output_class(tmp_output);Otherwise we clone an instance of 'output_class' and let it take care of the connection. Each clone of output_class will have its own set of global variables, which will enable many connections to be active at the same time without data being mixed up. Note that the programs will not actually run simultaneously though.
destruct(tmp_output);Destruct the object returned by accept(), output_class has already copied the contents of this object.
}Then there is main, the function that gets it all started.
int main(int argc, array(string) argv)Write an encouraging message to stderr.
{
werror("Starting minimal httpd\n");
if(!bind(PORT, accept_callback))Bind PORT and set it up to call accept_callback as soon as someone connects to it. If the bind() fails we write an error message and return the 17 to indicate failure.
{
werror("Failed to open socket (already bound?)\n");
return 17;
}
return - 17;If everything went ok, we return -17, any negative value returned by main() means that the program WON'T exit, it will hang around waiting for events instead. (like someone connecting)/* Keep going */
}That's it, this simple program can be used as the basis for a simple WWW-server. Note that today most WWW servers are very complicated programs, and the above program can never replace a modern WWW server. However, it is very fast if you only want a couple of web pages and have a slow machine available for the server.
10.1 Starting a thread
Starting a thread is very easy. You simply call thread_create with a function
pointer and any arguments it needs and that function will be executed in a
separate thread. The function thread_create will return immediately and both
the calling function and the called function will execute at the same time. Example:
void foo(int x)
This may all seem very simple, but there are a few complications to
watch out for:
{
for(int e=0;e<5;e++)
{
sleep(1);
write("Hello from thread "+x+".\n");
}
}
int main()
{
thread_create(foo, 2);
thread_create(foo, 3);
foo(1);
}
void mapadd(mapping m, int i, int j)
This is quite harmless as long as it is only used from one thread at a time,
but if two threads call it it at the same time, there is a slight chance that
both threads will discover that map[i] is zero and both threads will
then do map[i]=({j}); and one value of j will be lost.
This type of bug can be extremely hard to debug.
The above problem can be solved with the help of Mutexes and Condition
variables. Mutexes are basically a way to keep other threads out while a task
is being performed. Conditions, or condition variables, are used to inform
other threads that they don't have to wait any longer. Pike also provides
two different kinds of pipelines to send data from one thread to another, which
makes it very simple to write threaded programs. Let's look at an example:
{
if(map[i])
map[i]+=({j});
else
map[i]=({j});
}#!/usr/local/bin/pike
This is an example of a simple grep-like program. It looks for the string
given as first argument to the program in the files given as the rest
of the arguments. Don't worry if you do not understand it yet. Read the
descriptions of the functions and classes below and come back and read
this example again.
import Thread;
inherit Fifo;
inherit Fifo : ended;
void worker(string lookfor)
{
while(string file=Fifo::read())
{
int linenum=1;
object o=Stdio.FILE(file,"r");
while(string line=o->gets())
{
if(search(line, lookfor) >=0)
write(sprintf("%s:%d: %s\n",file, linenum, line));
linenum++;
}
}
ended::write(0);
}
int main(int argc, array(string) argv)
{
for(int e=0;e<4;e++)
thread_create(worker,argv[e]);
for(int e=2;e<argc;e++)
Fifo::write(argv[1]);
for(int e=0;e<4;e++)
Fifo::write(0);
for(int e=0;e<4;e++)
ended::read();
exit(0);
}10.2 Threads reference section
This section describes all thread-related functions and classes.
In POSIX threads, mutex locks can only be unlocked by the same thread locked them. In Pike any thread can unlock a locked mutex.
inherit Thread.Mutex : r_mutex;
inherit Thread.Mutex : w_mutex;
object r_lock=r_mutex::lock();
object w_lock;
mixed storage;
void write(mixed data)
{
w_lock=w_mutex::lock();
storage=data;
destruct(r_lock);
}
mixed read()
{
mixed tmp;
r_lock=r_mutex::lock();
tmp=storage;
storage=0;
destruct(w_lock);
return tmp;
}
// This program implements a fifo that can be used to send // data between two threads.
inherit Thread.Condition : r_cond;
inherit Thread.Condition: w_cond;
inherit Thread.Mutex: lock;
mixed *buffer = allocate(128);
int r_ptr, w_ptr;
int query_messages() { return w_ptr - r_ptr; }// This function reads one mixed value from the fifo. // If no values are available it blocks until a write has been done.
mixed read()
{
mixed tmp;
// We use this mutex lock to make sure no write() is executed
// between the query_messages and the wait() call. If it did
// we would wind up in a deadlock.
object key=lock::lock();
while(!query_messages()) r_cond::wait(key);
tmp=buffer[r_ptr++ % sizeof(buffer)];
w_cond::signal();
return tmp;
}// This function pushes one mixed value on the fifo. // If the fifo is full it blocks until a value has been read.
void write(mixed v)
{
object key=lock::lock();
while(query_messages() == sizeof(buffer)) w_cond::wait(key);
buffer[w_ptr++ % sizeof(buffer)]=v;
r_cond::signal();
}
#!/usr/local/bin/pike/* A very small threaded httpd capable of fetching files only. * Written by Fredrik H³binette as a demonstration of Pike */
import Thread;
inherit Stdio.Port;/* number of bytes to read for each write */
#define BLOCK 16384/* Where do we have the html files ? */
#define BASE "/home/hubbe/pike/src/"/* File to return when we can't find the file requested */
#define NOFILE "/home/hubbe/www/html/nofile.html"/* Port to open */
#define PORT 1905/* Number of threads to start */
#define THREADS 5// There will be one of these for each thread
class worker
{
inherit Stdio.FILE : socket;// For communication with the browser
inherit Stdio.File : file;// For reading the file from disc
void create(function accept)
{
string cmd, input, tmp;
while(1)
{
socket::close();// Close previous connection
file::close();
object o=accept();// Accept a connection
if(!o) continue;
socket::assign(o);
destruct(o);
// Read request
sscanf(socket::gets(),"%s %s%*[\012\015 \t]",cmd, input);
if(cmd!="GET")
{
werror("Only method GET is supported.\n");
continue;
}
// Open the requested file
sscanf(input,"%*[/]%s",input);
input=BASE+combine_path("/",input);
if(!file::open(input,"r"))
{
if(!file::open(NOFILE,"r"))
{
werror("Couldn't find default file.\n");
continue;
}
}
// Copy data to socket
while(socket::write(file::read(BLOCK))==BLOCK);
}
}
};
int main(int argc, array(string) argv)
{
werror("Starting minimal threaded httpd\n");
// Bind the port, don't set it nonblocking
if(!bind(PORT))
{
werror("Failed to open socket (already bound?)\n");
return 17;
}
// Start worker threads
for(int e=1;e<THREADS;e++) thread_create(worker,accept);
worker(accept);
}
As stated in the beginning of this chapter; Pike threads are only available
on some UNIX systems. The above example does not work if your system does
not have threads.
Chapter 11, Modules for specific data types
There are a few modules that provide extra functions that operate specifically
on one data type. These modules have the same name as the data type, but are
capitalized so you can tell the difference. At the time of writing, the only
such modules are String and Array, but more are expected to
show up in the future.
11.1 String
The module String contains some extra string functionality which
is not always used. These functions are mostly implemented in Pike as a
complement to those written in C.
Result: green
> implode_nicely(({"green","blue"}));
Result: green and blue
> implode_nicely(({"green","blue","white"}));
Result: green, blue and white
> implode_nicely(({"green","blue","white"}),"or");
Result: green, blue or white
Second syntax: Map array calls function fun in all objects in the array arr. ie. arr[x]=arr[x]->fun(@ args);
Third syntax: Map array calls the functions in the array arr: arr[x]=arr[x]->fun(@ args);
Second syntax: Filter array calls fun in all the objects in the array arr, and return all objects that returned true.
Third syntax: Filter array calls all function pointers in the array arr, and return all that returned true.
mixed *sum_arrays(function fun,mixed *arr1,...)
{
Simple ehh?
All images handled by this module are stored as 24-bit RGB images. This means that a 1024 pixel wide and 1024 pixel high image will use 1024*1024*3 bytes = 3 megabytes. It is quite easy to mess up and use up all the memory by giving the wrong argument to one of the scaling functions.
Most functions in this module work by creating a new Image and then returning that instead of changing the Image you are working with. This makes it possible to share the same image between many variables without having to worry that it will be changed by accident. This can reduce the amount of memory used.
Many functions in this module work with the 'current color', this can be thought of as the background color if you wish. To change the current color you use 'setcolor'.
Let's look at an example of how this can be used:
#!/usr/local/bin/pikeThis very simple example can be used as a CGI script to produce a gif image which says what time it is in white text on a black background.
int main()
{
write("Content-type: image/gif\n\n");
object font=Image.font();
font->load("testfont");
object image=font->write(ctime(time));
write(image->togif());
}
| Image.image | Basic image manipulation |
| Image.font | Creating images from text |
| Image.colortable | Color reduction, quantisation and dither |
| Image.GIF | GIF encoding/decoding capabilities |
| Image.PNM | PNM (PBM/PGM/PPM) encoding/decoding capabilities |
Image module documentation is based on these file versions:
$Id: blit.c,v 1.24 1997/11/24 16:11:55 mirar Exp $
$Id: blit_layer_include.h,v 1.4 1997/10/27 22:41:17 mirar Exp $
$Id: colortable.c,v 1.27 1997/11/29 22:47:39 mirar Exp $
$Id: colortable.h,v 1.10 1997/11/11 22:17:47 mirar Exp $
$Id: dct.c,v 1.9 1997/10/27 22:41:19 mirar Exp $
$Id: font.c,v 1.21 1997/11/11 22:17:48 mirar Exp $
$Id: image.c,v 1.69 1997/11/29 18:59:35 hedda Exp $
$Id: image.h,v 1.15 1997/11/23 05:28:29 per Exp $
$Id: matrix.c,v 1.10 1997/10/27 22:41:25 mirar Exp $
$Id: operator.c,v 1.9 1997/10/27 22:41:26 mirar Exp $
$Id: pattern.c,v 1.9 1997/11/02 18:49:11 grubba Exp $
$Id: pnm.c,v 1.8 1997/11/02 03:46:52 mirar Exp $
$Id: polyfill.c,v 1.15 1997/11/12 03:40:20 mirar Exp $
$Id: togif.c,v 1.28 1997/11/26 15:41:35 mirar Exp $
$Id: gif.c,v 1.20 1997/11/29 22:48:50 mirar Exp $
$Id: gif_lzw.c,v 1.4 1997/11/05 03:42:50 mirar Exp $
$Id: gif_lzw.h,v 1.4 1997/11/02 03:44:51 mirar Exp $
$Id: pnm.c,v 1.5 1997/11/29 21:33:36 grubba Exp $
The object has color reduction, quantisation, mapping and dithering capabilities.
add takes the same argument(s) as create, thus adding colors to the colortable.
The colortable is mostly a list of colors, or more advanced, colors and weight.
The colortable could also be a colorcube, with or without additional scales. A colorcube is the by-far fastest way to find colors.
Example:
ct=colortable(my_image,256); // the best 256 colors
ct=colortable(my_image,256,({0,0,0})); // black and the best other 255
ct=colortable(({({0,0,0}),({255,255,255})})); // black and white
ct=colortable(6,7,6); // a colortable of 252 colors
ct=colortable(7,7,5, ({0,0,0}),({255,255,255}),11);
// a colorcube of 245 colors, and a greyscale of the rest -> 256
| argument(s) | description |
| array(array(int)) colors | list of colors |
| object(Image.image) image | source image
note: you may not get all colors from image, max hash size is (probably, set by a #define) 32768 entries, giving maybe half that number of colors as maximum. |
| int number | number of colors to get from the image
0 (zero) gives all colors in the image.
Default value is 256. |
| array(array(int)) needed | needed colors (to optimize selection of others to these given) this will add to the total number of colors (see argument 'number') |
|
int r int g int b | size of sides in the colorcube, must (of course) be equal or larger than 2 - if smaller, the cube is ignored (no colors). This could be used to have only scales (like a greyscale) in the output. |
|
array(int) fromi array(int) toi int stepi | This is to add the possibility of adding a scale
of colors to the colorcube; for instance a grayscale
using the arguments ({0,0,0}),({255,255,255}),17,
adding a scale from black to white in 17 or more steps.
Colors already in the cube is used again to add the number of steps, if possible. The total number of colors in the table is therefore r*b*g+step1+...+stepn. |
example: (array)Image.colortable(img)
| argument(s) | description |
| string to | must be "array". |
The colorspace is divided in small cubes, each cube containing the colors in that cube. Each cube then gets a list of the colors in the cube, and the closest from the corners and midpoints between corners.
When a color is needed, the algorithm first finds the correct cube and then compares with all the colors in the list for that cube.
example: colors=Image.colortable(img)->cubicles();
algorithm time: between O[m] and O[m * n], where n is numbers of colors and m is number of pixels
The arguments can be heavy trimmed for the usage of your colortable; a large number (10ū10ū10 or bigger) of cubicles is recommended when you use the colortable repeatedly, since the calculation takes much more time than usage.
recommended values:
image size setup
100ū100 cubicles(4,5,4) (default)
1000ū1000 cubicles(12,12,12) (factor 2 faster than default)
In some cases, the full method is faster.
 |
 |
 |
| original | default cubicles, 16 colors |
accuracy=200 |
| argument(s) | description |
|
int r int g int b | Size, ie how much the colorspace is divided. Note that the size of each cubicle is at least about 8b, and that it takes time to calculate them. The number of cubicles are r*g*b, and default is 4,5,4, ie 80 cubicles. This works good for 200▒100 colors. |
| int accuracy | Accuracy when checking sides of cubicles. Default is 16. A value of 1 gives complete accuracy, ie cubicle() method gives exactly the same result as full(), but takes (in worst case) 16ū the time to calculate. |
Not applicable to colorcube types of colortable.
|
 |
 |
| original | floyd_steinberg to a 4ū4ū4 colorcube | floyd_steinberg to 16 chosen colors |
| argument(s) | description |
| int bidir | Set algorithm direction of forward. -1 is backward, 1 is forward, 0 for toggle of direction each line (default). |
|
int|float forward int|float downforward int|float down int|float downback | Set error correction directions. Default is forward=7, downforward=1, down=5, downback=3. |
| int|float factor | Error keeping factor. Error will increase if more than 1.0 and decrease if less than 1.0. A value of 0.0 will cancel any dither effects. Default is 0.95. |
example: colors=Image.colortable(img)->full();
algorithm time: O[n*m], where n is numbers of colors and m is number of pixels
 |
 |
 |
|
 |
no dither | |
 |
 |
 |
|
 |
floyd_steinberg dither | |
 |
 |
 |
 |
 |
ordered dither | |
|
 |
 |
 |
 |
 |
randomcube dither |
| original | 2 | 4 | 8 | 16 | 32 colors |
|
 |
 |
 |
| original | mapped to Image.colortable(6,6,6)-> |
||
| ordered (42,42,42,2,2) |
ordered() | ordered (42,42,42, 8,8, 0,0, 0,1, 1,0) |
|
 |
 |
 |
 |
| argument(s) | description |
|
int r int g int b | The maximum error. Default is 32, or colorcube steps (256/size). |
|
int xsize int ysize | Size of error matrix. Default is 8ū8. Only values which factors to multiples of 2 and 3 are possible to choose (2,3,4,6,8,12,...). |
|
int x int y int rx int ry int gx int gy int bx int by | Offset for the error matrix. x and y is for both red, green and blue values, the other is individual. |
The randomgrey method uses the same random error on red, green and blue and the randomcube method has three random errors.
|
 |
 |
| original | mapped to Image.colortable(4,4,4)-> |
|
| randomcube() | randomgrey() | |
|
 |
 |
| argument(s) | description |
|
int r int g int b int err | The maximum error. Default is 32, or colorcube step. |
All needed (see create) colors are kept.
| argument(s) | description |
| int colors | target number of colors |
Default factors are 3, 4 and 1; blue is much darker than green. Compare with Image.image->grey().
| argument(s) | description |
| object(colortable) with | colortable object with colors to add |
| argument(s) | description |
| object(colortable) with | colortable object with colors to subtract |
For simple usage, see write and load.
other methods: baseline, height, set_xspacing_scale, set_yspacing_scale, text_extents
struct file_head
{
unsigned INT32 cookie; - 0x464f4e54
unsigned INT32 version; - 1
unsigned INT32 chars; - number of chars
unsigned INT32 height; - height of font
unsigned INT32 baseline; - font baseline
unsigned INT32 o[1]; - position of char_head's
} *fh;
struct char_head
{
unsigned INT32 width; - width of this character
unsigned INT32 spacing; - spacing to next character
unsigned char data[1]; - pixmap data (1byte/pixel)
} *ch;
| argument(s) | description |
| string text, ... | One or more lines of text. |
| argument(s) | description |
| string filename | Font file |
| argument(s) | description |
| float scale | what scale to use |
| argument(s) | description |
| string text, ... | One or more lines of text. |
init: clear, clone, create, xsize, ysize
plain drawing: box, circle, getpixel, line, setcolor, setpixel, threshold, tuned_box, polyfill
pasting images, layers: add_layers, paste, paste_alpha, paste_alpha_color, paste_mask
getting subimages, scaling, rotating: autocrop, clone, copy, dct, mirrorx, rotate, rotate_expand, rotate_ccw, rotate_cw, scale, skewx, skewx_expand, skewy, skewy_expand
calculation by pixels: apply_matrix, change_color, color, distancesq, grey, invert, modify_by_intensity, select_from, rgb_to_hsv, hsv_to_rgb, Image.colortable
converting to other datatypes: Image.GIF, Image.PNM
special pattern drawing: noise, turbulence
The destination image can also be cropped, thus speeding up the process.
Each array in the layers array is one of:
({object image,object|int mask})
({object image,object|int mask,int opaque_value})
({object image,object|int mask,int opaque_value,int method})
Given 0 as mask means the image is totally opaque.
Default opaque value is 255, only using the mask.
Methods for now are:
0 no operation (just paste with mask, default)
1 maximum (`|)
2 minimum (`&)
3 multiply (`*)
4 add (`+)
5 diff (`-)
The layer image and the current source are calculated
through the given method and then pasted using the mask
and the opaque channel value.
All given images must be the same size.
| argument(s) | description |
| array(int|object) layer0 | image to paste |
|
int x1 int y1 int x2 int y2 | rectangle for cropping |
2 2
pixel(x,y)= base+ k ( sum sum pixel(x+k-1,y+l-1)*matrix(k,l) )
k=0 l=0
1/k is sum of matrix, or sum of matrix multiplied with div.
base is given by r,g,b and is normally black.
blur (ie a 2d gauss function):
({({1,2,1}),
({2,5,2}),
({1,2,1})})
|

|
|
| original | ||
sharpen (k>8, preferably 12 or 16):
({({-1,-1,-1}),
({-1, k,-1}),
({-1,-1,-1})})
|

| |
edge detect:
({({1, 1,1}),
({1,-8,1}),
({1, 1,1})})
|

| |
horisontal edge detect (get the idea):
({({0, 0,0}),
({1,-2,1}),
({0, 0,0})})
|

| |
emboss (might prefer to begin with a grey image):
({({2, 1, 0}),
({1, 0,-1}),
({0,-1,-2})}), 128,128,128, 3
|

|

|
| greyed |
This function is not very fast.
| argument(s) | description |
| array(array(int|array(int))) | the matrix; innermost is a value or an array with red, green, blue values for red, green, blue separation. |
|
int r int g int b | base level of result, default is zero |
| int|float div | division factor, default is 1.0. |
"Unneccesary" is all pixels that are equal -- ie if all the same pixels to the left are the same color, that column of pixels are removed.
| argument(s) | description |
| int border | added border size in pixels |
|
int r int g int b | color of the new border |
|
int left int right int top int bottom | which borders to scan and cut the image;
a typical example is removing the top and bottom unneccesary
pixels:
img=img->autocrop(0, 0,0,1,1); |
| argument(s) | description |
|
int x1 int y1 int x2 int y2 | box corners |
|
int r int g int b | color of the box |
| int alpha | alpha value |
| argument(s) | description |
|
int tor int tog int tob | destination color and next current color |
|
int fromr int fromg int fromb | source color, default is current color |
| argument(s) | description |
|
int x int y | circle center |
|
int rx int ry | circle radius in pixels |
|
int r int g int b | color |
| int alpha | alpha value |
| argument(s) | description |
|
int r int g int b | color of the new image |
| int alpha | new default alpha channel value |
| argument(s) | description |
|
int xsize int ysize | size of (new) image in pixels, called image is cropped to that size |
|
int r int g int b | current color of the new image, default is black. Will also be the background color if the cloned image is empty (no drawing area made). |
| int alpha | new default alpha channel value |
The red, green and blue values of the pixels are multiplied with the given value(s). This works best on a grey image...
The result is divided by 255, giving correct pixel values.
If no arguments are given, the current color is used as factors.
|
 |
| original | ->color(128,128,255); |
| argument(s) | description |
|
int r int g int b | red, green, blue factors |
| int value | factor |
| argument(s) | description |
|
int x1 int y1 int x2 int y2 | The requested new area. Default is the old image size. |
|
int r int g int b | color of the new image |
| int alpha | new default alpha channel value |
| argument(s) | description |
|
int xsize int ysize | size of (new) image in pixels |
|
int r int g int b | background color (will also be current color), default color is black |
| int alpha | default alpha channel value |
This gives a quality-conserving upscale, but the algorithm used is n*n+n*m, where n and m is pixels in the original and new image.
Recommended wrapping algorithm is to scale overlapping parts of the image-to-be-scaled.
This functionality is actually added as an true experiment, but works...
| argument(s) | description |
|
int newx int newy | new image size in pixels |
p = pixel color
o = given color
d = destination pixel
d.red=d.blue=d.green=
((o.red-p.red)▓+(o.green-p.green)▓+(o.blue-p.blue)▓)>>8
|
 |
| original | ->distancesq(255,0,128); |
| argument(s) | description |
|
int r int g int b | red, green, blue coordinates |
| argument(s) | description |
| string pnm | pnm data, as a string |
| argument(s) | description |
|
int x int y | position of the pixel |
| is replaced by | |
| gif_begin | Image.GIF.header_block |
| gif_end | Image.GIF.end_block |
| gif_netscape_loop | Image.GIF.netscape_loop_block |
| togif | Image.GIF.encode |
| togif_fs | Image.GIF.encode╣ |
| gif_add | Image.GIF.render_block╣▓ |
| gif_add_fs | Image.GIF.render_block╣ |
| gif_add_nomap | Image.GIF.render_block▓ |
| gif_add_fs_nomap | Image.GIF.render_block╣▓ |
╣ Use Image.colortable to get whatever dithering you want.
▓ local map toggle is sent as an argument
|
 |
 |
| original | ->grey(); | ->grey(0,0,255); |
| argument(s) | description |
|
int r int g int b | weight of color, default is r=87,g=127,b=41, which should be pretty accurate of what the eyes see... |
When converting to RGB, the input data is asumed to be placed in the pixels as above.
|
 |
 |
| original | ->hsv_to_rgb(); | ->rgb_to_hsv(); |
 |
 |
 |
| tuned box (below) | the rainbow (below) | same, but rgb_to_hsv() |
HSV to RGB calculation:
in = input pixel
out = destination pixel
h=-pos*c_angle*3.1415/(float)NUM_SQUARES;
out.r=(in.b+in.g*cos(in.r));
out.g=(in.b+in.g*cos(in.r + pi*2/3));
out.b=(in.b+in.g*cos(in.r + pi*4/3));
RGB to HSV calculation: Hmm.
Example: Nice rainbow.
object i = Image.image(200,200);
i = i->tuned_box(0,0, 200,200,
({ ({ 255,255,128 }), ({ 0,255,128 }),
({ 255,255,255 }), ({ 0,255,255 })}))
->hsv_to_rgb();
|
 |
 |
| original | ->invert(); | ->rgb_to_hsv()->invert()->hsv_to_rgb(); |
| argument(s) | description |
|
int x1 int y1 int x2 int y2 | line endpoints |
|
int r int g int b | color |
| int alpha | alpha value |
Replacement examples:
Old code:
img=map_fs(img->select_colors(200));New code:
img=Image.colortable(img,200)->floyd_steinberg()->map(img);
Old code:
img=map_closest(img->select_colors(17)+({({255,255,255}),({0,0,0})}));
New code:
img=Image.colortable(img,19,({({255,255,255}),({0,0,0})}))->map(img);
|
 |
| original | ->mirrorx(); |
|
 |
| original | ->mirrory(); |
For each color an intensity is calculated, from r, g and b factors (see grey), this gives a value between 0 and max.
The color is then calculated from the values given, v1 representing the intensity value of 0, vn representing max, and colors between representing intensity values between, linear.
|
 |
| original | ->grey()->modify_by_intensity(1,0,0, 0,({255,0,0}),({0,255,0})); |
| argument(s) | description |
|
int r int g int b | red, green, blue intensity factors |
|
int|array(int) v1 int|array(int) vn | destination color |
The random seed may be different with each instance of pike.
Example:
->noise( ({0,({255,0,0}), 0.3,({0,255,0}), 0.6,({0,0,255}), 0.8,({255,255,0})}), 0.005,0,0,0.5 );

| argument(s) | description |
| array(float|int|array(int)) colorrange | colorrange table |
| float scale | default value is 0.1 |
|
float xdiff float ydiff | default value is 0,0 |
| float cscale | default value is 1 |
| argument(s) | description |
| object image | image to paste (may be empty, needs to be an image object) |
|
int x int y | where to paste the image; default is 0,0 |
| argument(s) | description |
| object image | image to paste |
| int alpha | alpha channel value |
|
int x int y | where to paste the image; default is 0,0 |
| argument(s) | description |
| object mask | mask image |
|
int r int g int b | what color to paint with; default is current |
|
int x int y | where to paste the image; default is 0,0 |
The masks red, green and blue values are used separately.
| argument(s) | description |
| object image | image to paste |
| object mask | mask image |
|
int x int y | where to paste the image; default is 0,0 |
| argument(s) | description |
| array(int|float) curve | curve(s), ({x1,y1,x2,y2,...,xn,yn}),
automatically closed.
If any given curve is inside another, it will make a hole. |
The string is nullpadded or cut to fit.
| argument(s) | description |
| string what | the hidden message |
|
 |
 |
| original | ->rotate(15,255,0,0); | ->rotate_expand(15); |
The "expand" variant of functions stretches the image border pixels rather then filling with the given or current color.
This rotate uses the skewx() and skewy() functions.
| argument(s) | description |
| int|float angle | the number of degrees to rotate |
|
int r int g int b | color to fill with; default is current |
|
 |
| original | ->rotate_ccw(); |
|
 |
| original | ->rotate_cw(); |
| argument(s) | description |
| float factor | factor to use for both x and y |
|
float xfactor float yfactor | separate factors for x and y |
| argument(s) | description |
|
int newxsize int newysize | new image size in pixels |
When the edge distance is reached, the scan is stopped. Default edge value is 30. This value is squared and compared with the square of the distance above.
| argument(s) | description |
|
int x int y | originating pixel in the image |
| argument(s) | description |
|
int r int g int b | new color |
| int alpha | new alpha value |
| argument(s) | description |
|
int x int y | position of the pixel |
|
int r int g int b | color |
| int alpha | alpha value |
|
 |
 |
| original | ->skewx(15,255,0,0); | ->skewx_expand(15); |
| argument(s) | description |
| int x | the number of pixels The "expand" variant of functions stretches the image border pixels rather then filling with the given or current color. |
| float yfactor | best described as: x=yfactor*this->ysize() |
|
int r int g int b | color to fill with; default is current |
|
 |
 |
| original | ->skewy(15,255,0,0); | ->skewy_expand(15); |
The "expand" variant of functions stretches the image border pixels rather then filling with the given or current color.
| argument(s) | description |
| int y | the number of pixels |
| float xfactor | best described as: t=xfactor*this->xsize() |
|
int r int g int b | color to fill with; default is current |
If all red, green, blue parts of a pixel is larger or equal then the given value, the pixel will become white, else black.
This method works fine with the grey method.
If no arguments are given, the current color is used for threshold values.
|
 |
| original | ->threshold(90,100,110); |
| argument(s) | description |
|
int r int g int b | red, green, blue threshold values |
Tuning function is (1.0-x/xw)*(1.0-y/yw) where x and y is the distance to the corner and xw and yw are the sides of the rectangle.
|
 |
 |
| original | solid tuning (blue,red,green,yellow) |
tuning transparency (as left + 255,128,128,0) |
| argument(s) | description |
|
int x1 int y1 int x2 int y2 | rectangle corners |
| array(array(int)) corner_color | colors of the corners:
({x1y1,x2y1,x1y2,x2y2})
each of these is an array of integeres:
({r,g,b}) or ({r,g,b,alpha})
Default alpha channel value is 0 (opaque). |
The random seed may be different with each instance of pike.
Example:
->turbulence( ({0,({229,204,204}), 0.9,({229,20,20}), 0.9,0}) );

| argument(s) | description |
| array(float|int|array(int)) colorrange | colorrange table |
| int octaves | default value is 3 |
| float scale | default value is 0.1 |
|
float xdiff float ydiff | default value is 0,0 |
| float cscale | default value is 1 |
| argument(s) | description |
| object operand | the other image to compare with; the images must have the same size. |
| array(int) color | an array in format ({r,g,b}), this is equal to using an uniform-colored image. |
| int value | equal to ({value,value,value}). |
This can be useful to lower the values of an image, making it greyer, for instance:
image=image*128+64;
| argument(s) | description |
| object operand | the other image to multiply with; the images must have the same size. |
| array(int) color | an array in format ({r,g,b}), this is equal to using an uniform-colored image. |
| int value | equal to ({value,value,value}). |
| argument(s) | description |
| object operand | the image which to add. |
| array(int) color | an array in format ({r,g,b}), this is equal to using an uniform-colored image. |
| int value | equal to ({value,value,value}). |
| argument(s) | description |
| object operand | the other image to compare with; the images must have the same size. |
| array(int) color | an array in format ({r,g,b}), this is equal to using an uniform-colored image. |
| int value | equal to ({value,value,value}). |
| argument(s) | description |
| object operand | the other image to compare with; the images must have the same size. |
| array(int) color | an array in format ({r,g,b}), this is equal to using an uniform-colored image. |
| int value | equal to ({value,value,value}). |
GIF is a common image storage format, usable for a limited color palette - a GIF image can only contain as most 256 colors - and animations.
Simple encoding: encode, encode_trans
Advanced stuff: render_block, header_block, end_block, netscape_loop_block
Very advanced stuff: _render_block, _gce_block
The latter (encode_trans) functions add transparency capabilities.
Example:
img=Image.image([...]);
[...] // make your very-nice image
write(Image.GIF.encode(img)); // write it as GIF on stdout
| argument(s) | description |
| object img | The image which to encode. |
|
int colors object colortable | These arguments decides what colors the image should be encoded with. If a number is given, a colortable with be created with (at most) that amount of colors. Default is '256' (GIF maximum amount of colors). |
| object alpha | Alpha channel image (defining what is transparent); black
color indicates transparency. GIF has only transparent
or nontransparent (no real alpha channel).
You can always dither a transparency channel:
Image.colortable(my_alpha, ({({0,0,0}),({255,255,255})})) |
|
int tr_r int tr_g int tr_b | Use this (or the color closest to this) color as transparent pixels. |
|
int a_r int a_g int a_b | Encode transparent pixels (given by alpha channel image) to have this color. This option is for making GIFs for the decoders that doesn't support transparency. |
| int transp_index | Use this color no in the colortable as transparent color. |
Image.GIF.encode_trans(img,colortable,alpha);is equivalent of using
Image.GIF.header_block(img->xsize(),img->ysize(),colortable)+
Image.GIF.render_block(img,colortable,0,0,0,alpha)+
Image.GIF.end_block();
and is actually implemented that way.
The result of this function is always ";" or "\x3b", but I recommend using this function anyway for code clearity.
Giving a colortable to this function includes a global palette in the header block.
| argument(s) | description |
|
int xsize int ysize | Size of drawing area. Usually same size as in the first (or only) render block(s). |
| int background_color_index | This color in the palette is the background color. Background is visible if the following render block(s) doesn't fill the drawing area or are transparent. Most decoders doesn't use this value, though. |
| int gif87a | If set, write 'GIF87a' instead of 'GIF89a' (default 0 == 89a). |
|
int aspectx int aspecty | Aspect ratio of pixels, ranging from 4:1 to 1:4 in increments of 1/16th. Ignored by most decoders. If any of aspectx or aspecty is zero, aspectratio information is skipped. |
|
int r int g int b | Add this color as the transparent color. This is the color used as transparency color in case of alpha-channel given as image object. This increases (!) the number of colors by one. |
This GIF encoder doesn't support different size of colors in global palette and color resolution.
| argument(s) | description |
| int number_of_loops | Number of loops. Max and default is 65535. |
Example:
img1=Image.image([...]);
img2=Image.image([...]);
[...] // make your very-nice images
nct=Image.colortable([...]); // make a nice colortable
write(Image.GIF.header_block(xsize,ysize,nct)); // write a GIF header
write(Image.GIF.render_block(img1,nct,0,0,0,10)); // write a render block
write(Image.GIF.render_block(img2,nct,0,0,0,10)); // write a render block
[...]
write(Image.GIF.end_block()); // write end block
// voila! A GIF animation on stdout.
 The above animation is thus created:
The above animation is thus created:
object nct=colortable(lena,32,({({0,0,0})}));
string s=GIF.header_block(lena->xsize(),lena->ysize(),nct);
foreach ( ({lena->xsize(),
(int)(lena->xsize()*0.75),
(int)(lena->xsize()*0.5),
(int)(lena->xsize()*0.25),
(int)(1),
(int)(lena->xsize()*0.25),
(int)(lena->xsize()*0.5),
(int)(lena->xsize()*0.75)}),int xsize)
{
object o=lena->scale(xsize,lena->ysize());
object p=lena->clear(0,0,0);
p->paste(o,(lena->xsize()-o->xsize())/2,0);
s+=GIF.render_block(p,nct,0,0,0,25);
}
s+=GIF.netscape_loop_block(200);
s+=GIF.end_block();
write(s);
| argument(s) | description |
| object img | The image. |
| object colortable | Colortable with colors to use and to write as palette. |
|
int x int y | Position of this image. |
| int localpalette | If set, writes a local palette. |
| object alpha | Alpha channel image; black is transparent. |
|
int r int g int b | Color of transparent pixels. Not all decoders understands transparency. This is ignored if localpalette isn't set. |
| int delay | View this image for this many centiseconds. Default is zero. |
| int transp_index | Index of the transparent color in the colortable. -1 indicates no transparency. |
| int user_input | If set: wait the delay or until user input. If delay is zero, wait indefinitely for user input. May sound the bell upon decoding. Default is non-set. |
| int disposal | Disposal method number;
|
The user_input and disposal method are unsupported in most decoders.
| argument(s) | description |
|
int transparency int transparency_index | The following image has transparency, marked with this index. |
| int delay | View the following rendering for this many centiseconds (0..65535). |
| int user_input | Wait the delay or until user input. If delay is zero, wait indefinitely for user input. May sound the bell upon decoding. |
| int disposal | Disposal method number;
|
Most decoders just ignore some or all of these parameters.
| argument(s) | description |
|
int x int y | Position of this image. |
|
int xsize int ysize | Size of the image. Length if the indices string must be xsize*ysize. |
| int bpp | Bits per pixels in the indices. Valid range 1..8. |
| string indices | The image indices as an 8bit indices. |
| string colortable | Colortable with colors to write as palette. If this argument is zero, no local colortable is written. Colortable string len must be 1<<bpp. |
| int interlace | Interlace index data and set interlace bit. The given string should _not_ be pre-interlaced. |
PNM is a common image storage format on unix systems, and is a very simple format.
This format doesn't use any color palette.
The format is divided into seven subformats;
P1(PBM) - ascii bitmap (only two colors)
P2(PGM) - ascii greymap (only grey levels)
P3(PPM) - ascii truecolor
P4(PBM) - binary bitmap
P5(PGM) - binary greymap
P6(PPM) - binary truecolor
Simple encoding:
encode,
encode_binary,
encode_ascii
Simple decoding:
decode
Advanced encoding:
encode_P1,
encode_P2,
encode_P3,
encode_P4,
encode_P5,
encode_P6
encode_binary() and encode_ascii() uses the most optimized encoding for this image (bitmap, grey or truecolor) - P4, P5 or P6 respective P1, P2 or P3.
encode() maps to encode_binary().
Please note that these functions are available globally, you do not need to import System to use these functions.
This function only exists on systems that have the chroot(2) system call. The second variant only works on systems that also have the fchroot(2) system call.
The returned array contains the same information as that returned by gethostbyname().
The array contains three elements:
The first element is the hostname.
The second element is an array(string) of IP numbers for the host.
The third element is an array(string) of aliases for the host.
If pid is specified, returns the process group ID of that process.
The ident argument specifies an identifier to tag all log entries with.
options is a bit field specifying the behavior of the message logging. Valid options are:
| LOG_PID | Log the process ID with each message. |
| LOG_CONS | Write messages to the console if they can't be sent to syslogd. |
| LOG_NDELAY | Open the connection to syslogd now and not later. |
| LOG_NOWAIT | Do not wait for subprocesses talking to syslogd. |
facility specifies what subsystem you want to log as. Valid facilities are:
| LOG_AUTH | Authorization subsystem |
| LOG_AUTHPRIV | |
| LOG_CRON | Crontab subsystem |
| LOG_DAEMON | System daemons |
| LOG_KERN | Kernel subsystem (NOT USABLE) |
| LOG_LOCAL | For local use |
| LOG_LOCAL[1-7] | For local use |
| LOG_LPR | Line printer spooling system |
| LOG_MAIL | Mail subsystem |
| LOG_NEWS | Network news subsystem |
| LOG_SYSLOG | |
| LOG_USER | |
| LOG_UUCP | UUCP subsystem |
The mapping contains the following fields:
| "sysname": | Operating system name | |
| "nodename": "release": "version": "machine": | Host name Release of this OS Version number of this OS Machine architecture |
A regular expression is actually a string, then compiled into an object. The string contains characters that make up a pattern for other strings to match. Normal characters, such as A through Z only match themselves, but some characters have special meaning.
| pattern | Matches |
|---|---|
| . | any one character |
| [abc] | a, b or c |
| [a-z] | any character a to z inclusive |
| [^ac] | any character except a and c |
| (x) | x (x might be any regexp) If used with split, this also puts the string matching x into the result array. |
| x* | zero or more occurrences of 'x' (x may be any regexp) |
| x+ | one or more occurrences of 'x' (x may be any regexp) |
| x|y | x or y. (x or y may be any regexp) |
| xy | xy (x and y may be any regexp) |
| ^ | beginning of string (but no characters) |
| $ | end of string (but no characters) |
| \< | the beginning of a word (but no characters) |
| \> | the end of a word (but no characters) |
| Regexp | Matches |
|---|---|
| [0-9]+ | one or more digits |
| [^ \t\n] | exactly one non-whitespace character |
| (foo)|(bar) | either 'foo' or 'bar' |
| \.html$ | any string ending in '.html' |
| ^\. | any string starting with a period |
Note that \ can be used to quote these characters in which case they match themselves, nothing else. Also note that when quoting these something in Pike you need two \ because Pike also uses this character for quoting.
To make make regexps fast, they are compiled in a similar way that Pike is, they can then be used over and over again without needing to be recompiled. To give the user full control over the compilations and use of regexp an object oriented interface is provided.
You might wonder what regexps are good for, hopefully it should be more clear when you read about the following functions:
The Gmp library can handle large integers, floats and rational numbers, but
currently Pike only has support for large integers. The others will be added
later or when demand arises. Large integers are implemented as objects cloned
from Gmp.Mpz.
The mpz object implements all the normal integer operations.
(except xor) There are also some extra operators:
This is the an interface to the gdbm library. This module might or might not be available in your Pike depending on whether the gdbm library was available on your system when Pike was compiled.
| r | open database for reading |
| w | open database for writing |
| c | create database if it does not exist |
| t | overwrite existing database |
| f | fast mode |
The fast mode prevents the database from synchronizing each change in the database immediately. This is dangerous because the database can be left in an unusable state if Pike is terminated abnormally.
The default mode is "rwc".
mixed find_option(array(string) argv,
Also, as an extra bonus: shortform, longform and envvar can all be arrays, in which case either of the options in the array will be accpted.
int main(int argc, array(string) argv)
array find_all_options(array(string) argv, array option, int|void posix_me_harder, int|void throw_errors);
Each element in the array options should be an array on the following form:
> Getopt.find_all_options(({"test","-dd"}),
>> ({ ({ "debug", Getopt.NO_ARG, ({"-d","--debug"}), "DEBUG", 1}) }));
Result: ({
({ "debug", 1 }),
({ "debug", 1 })
})
This is what it would look like in real code:
import Getopt;
int debug=0;
int main(int argc, array(string) argv
{
foreach(find_all_options(argv, ({
({ "debug", MAY_HAVE_ARG, ({"-d","--debug"}), "DEBUG", 1}),
({ "version", NO_ARG, ({"-v","--version" }) }) })),
mixed option)
{
switch(option[0])
{
case "debug": debug+=option[1]; break;
case "version":
write("Test program version 1.0\n");
exit(1);
}
}
argv=Getopt.get_args(argv);
}
This function can also be used to re-initialize a Gz.deflate object so it can be re-used.
| Gz.NO_FLUSH | Only data that doesn't fit in the internal buffers is returned. |
| Gz.PARTIAL_FLUSH | All input is packed and returned. |
| Gz.SYNC_FLUSH | All input is packed and returned. |
| Gz.FINISH | All input is packed and an 'end of data' marker is appended. |
Using flushing will degrade packing. Normally NO_FLUSH should be used until the end of the data when FINISH should be used. For interactive data PARTIAL_FLUSH should be used.
// streaming (blocks)
function inflate=Gz.inflate()->inflate;
while(string s=stdin->read(8192))
If there is no YP server available for the domain, this function call will block until there is one. If no server appears in about ten minutes or so, an error will be returned. The timeout is not configurable from the C interface to Yp either.
If no domain is given, the default domain will be used. (As returned by Yp.default_yp_domain)
arguments is the map Yp-map to search in. This must be a full map name, for example, you should use passwd.byname instead of just passwd. key is the key to search for. The key must match exactly, no pattern matching of any kind is done.
object dom = Yp.YpDomain();
write(dom->match("passwd.byname", "root"));
If there is no YP server available for the domain, this function call will block until there is one. If no server appears in about ten minutes or so, an error will be returned. The timeout is not configurable from the C-yp interface either. map is the YP-map to bind to. This must be the full map name, as an example, passwd.byname instead of just passwd. If no domain is specified, the default domain will be used. This is usually best.
import Yp;
void print_entry(string key, string val)
{
val = (val/":")[4];
if(strlen(val))
{
string q = ".......... ";
werror(key+q[strlen(key)..]+val+"\n");
}
}
void main(int argc, array(string) argv)
{
object (YpMap) o = YpMap("passwd.byname");
werror("server.... "+ o->server() + "\n"
"age....... "+ (-o->order()+time()) + "\n"
"per....... "+ o["per"] + "\n"
"size...... "+ sizeof(o) + "\n");
o->map(print_entry);// Print username/GECOS pairs
}
The Message class does not make any interpretation of the body data, unless
the content type is multipart. A multipart message contains several
individual messages separated by boundary strings. The create
method of the Message class will divide a multipart body on these boundaries,
and then create individual Message objects for each part. These objects
will be collected in the array body_parts within the original
Message object. If any of the new Message objects have a body of type
multipart, the process is of course repeated recursively. The following
figure illustrates a multipart message containing three parts, one of
which contains plain text, one containing a graphical image, and the third
containing raw uninterpreted data:

> Array.map("=?iso-8859-1?b?S2lscm95?= was =?us-ascii?q?h=65re?="/" ",
MIME.decode_word);
Result: ({ /* 3 elements */
({ /* 2 elements */
"Kilroy",
"iso-8859-1"
}),
({ /* 2 elements */
"was",
0
}),
({ /* 2 elements */
"here",
"us-ascii"
})
})
> MIME.encode_word( ({ "Quetzalcoatl", "iso-8859-1" }), "base64" );
Result: =?iso-8859-1?b?UXVldHphbGNvYXRs?=
> MIME.encode_word( ({ "Foo", 0 }), "base64" );
Result: Foo
| type | subtype |
|---|---|
| text | plain |
| message | rfc822 |
| multipart | mixed |
The result is returned in the form of an array containing two elements. The first element is a mapping containing the headers found. The second element is a string containing the body.
> MIME.quote( ({ "attachment", ';', "filename", '=', "/usr/dict/words" }) );
Result: attachment;filename="/usr/dict/words"
Should the function succeed in reconstructing the original message, a new MIME.Message object is returned. Note that this message may in turn be a part of another, larger, fragmented message. If the function fails to reconstruct an original message, it returns an integer indicating the reason for its failure:
> MIME.tokenize("multipart/mixed; boundary=\"foo/bar\" (Kilroy was here)");
Result: ({ /* 7 elements */
"multipart",
47,
"mixed",
59,
"boundary",
61,
"foo/bar"
})
The set of special-characters is the one specified in RFC1521 (i.e. "<", ">", "@", ",", ";", ":", "\", "/", "?", "="), and not the one specified in RFC822.
> object msg = MIME.Message( "Hello, world!",
([ "MIME-Version" : "1.0",
"Content-Type":"text/plain",
"Content-Transfer-Encoding":"base64" ]) );
Result: object
> (string )msg;
Result: Content-Type: text/plain
Content-Length: 20
Content-Transfer-Encoding: base64
MIME-Version: 1.0
SGVsbG8sIHdvcmxkIQ==
> object msg = MIME.Message( "Hello, world!",
([ "MIME-Version" : "1.0",
"Content-Type" : "text/plain; charset=iso-8859-1" ]) );
Result: object
> msg->charset;
Result: iso-8859-1
Simulate inherits the Array, Stdio, String and Process modules, so importing he Simulate module also imports all identifiers from these modules. In addition, these functions are available:
mixed *filter_array(mixed *arr,function fun,mixed ... args);
or
mixed *filter_array(object *arr,string fun,mixed ... args);
or
mixed *filter_array(function *arr,-1,mixed ... args);
This function is the same as multiplication.
int sum(int ... i);
or
float sum(float ... f);
or
string sum(string|float|int ... p);
or
array sum(array ... a);
or
mapping sum(mapping ... m);
or
list sum(multiset ... l);
It currently works similar to old C preprocessors but has a few extra features. This chapter describes the different preprocessor directives. This is what it can do:
#!/usr/local/bin/pike
which will cause all subsequent occurrences of 'identifier' to be replaced with the replacement string.
Define also has the capability to use arguments, thus a line like
would cause identifier to be a macro. All occurrences of 'identifier(something1,something2d)' would be replaced with the replacement string. And in the replacement string, arg1 and arg2 will be replaced with something1 and something2.
#define foo bar // a comment
The comment will be included in the define, and thus inserted in the code. This will have the effect that the rest of the line will be ignored when the word foo is used. Not exactly what you might expect.
#define A "test"
#define B 17
#define C(X) (X)+(B)+"\n"
#define W write
#define Z Stdio.stdout
int main()
{
Z->W(C(A));
}
Expressions given to #if, #elif or #endif are special, all identifiers evaluate to zero unless they are defined to something else. Integers, strings and floats are the only types that can be used, but all pike operators can be used on these types.
Also, two special functions can be used, defined() and constant(). defined(identifier) expands to 1 if identifier is defined and 0 otherwise. constant(identifier) expands to 1 if identifier is an predefined constant (with add_constant), 0 otherwise.
#if defined(FOO)
#if !constant(write_file)
inherit "simulate.pike"
#endif
This can also be used when generating Pike from something else, to tell the compiler where the code originally originated from.
Calling add_constant without a value will remove that name from the list of constants. As with replacing, this will not affect already compiled programs.
mixed *aggregate(mixed ... elems) { return elems; }
multiset aggregate(mixed ... elems) { return mkmultiset(elems); }
The only problem is that mkmultiset is implemented using aggregate_multiset...
If seconds is zero, no new alarm is scheduled.
In any event any previously set alarm is canceled.
({
| file, | /* a string with the filename if known, else zero */ |
| line, | /* an integer containing the line if known, else zero */ |
| function, | /* The function pointer to the called function */ |
| mixed|void ..., | /* The arguments the function was called with */ |
The current call frame will be last in the array, and the one above that the last but one and so on.
({
| time_left, | /* an int */ |
| caller, | /* the object that made the call out */ |
| function, | /* the function to be called */ |
| arg1, | /* the first argument, if any */ |
| arg2, | /* the second argument, if any */ |
| ... | /* and so on... */ |
As a side-effect, this function sets the value returned by time(1) to the current time.
map_array(data, lambda(mixed x,mixed y) { return x[y]; }, index)Except of course it is a lot shorter and faster. That is, it indexes every index in the array data on the value of the argument index and returns an array with the results.
> column( ({ ({1,2}), ({3,4}), ({5,6}) }), 1)
Result: ({2, 4, 6})
Almost any value can be coded, mappings, floats, arrays, circular structures etc. At present, objects, programs and functions cannot be saved in this way. This is being worked on.
| mode, | /* file mode, protection bits etc. etc. */ |
| size, | /* file size for regular files, -2 for dirs, -3 for links, -4 for otherwise */ |
| atime, | /* last access time */ |
| mtime, | /* last modify time */ |
| ctime, | /* last status time change */ |
| uid, | /* The user who owns this file */ |
| gid | /* The group this file belongs to */ |
If there is no such file or directory, zero is returned.
Some signals and their supposed purpose:
| SIGHUP | Hang-up, sent to process when user logs out |
| SIGINT | Interrupt, normally sent by ctrl-c |
| SIGQUIT | Quit, sent by ctrl-\ |
| SIGILL | Illegal instruction |
| SIGTRAP | Trap, mostly used by debuggers |
| SIGABRT | Aborts process, can be caught, used by Pike whenever something goes seriously wrong. |
| SIGBUS | Bus error |
| SIGFPE | Floating point error (such as division by zero) |
| SIGKILL | Really kill a process, cannot be caught |
| SIGUSR1 | Signal reserved for whatever you want to use it for. |
| SIGSEGV | Segmentation fault, caused by accessing memory where you shouldn't. Should never happen to Pike. |
| SIGUSR2 | Signal reserved for whatever you want to use it for. |
| SIGALRM | Signal used for timer interrupts. |
| SIGTERM | Termination signal |
| SIGSTKFLT | Stack fault |
| SIGCHLD | Child process died |
| SIGCONT | Continue suspended |
| SIGSTOP | Stop process |
| SIGSTP | Suspend process |
| SIGTTIN | tty input for background process |
| SIGTTOU | tty output for background process |
| SIGXCPU | Out of CPU |
| SIGXFSZ | File size limit exceeded |
| SIGPROF | Profile trap |
| SIGWINCH | Window change signal |
Note that you have to use signame to translate the name of a signal to its number.
When a module is loaded the functions init_module_efuns and init_module_programs are called to initialize it. When Pike exits exit_module is called in all dynamically loaded modules. These functions _must_ be available in the module.
Please see the source and any examples available at ftp://www.idonex.se/pub/pike for more information on how to write modules for Pike in C.
| sec | seconds over the minute | 0 - 59 |
| min | minutes over the hour | 0 - 59 |
| hour | what hour in the day | 0 - 23 |
| mday | day of the month | 1 - 31 |
| mon | what month | 0 - 11 |
| year | years since 1900 | 0 - |
| wday | day of week (0=Sunday) | 0 - 6 |
| yday | day of year | 0 - 365 |
| isdst | is daylight saving time | 0/1 |
| timezone | difference between local time and UTC |
| year | The number of years since 1900 |
| mon | The month |
| mday | The day of the month. |
| hour | The number of hours past midnight |
| min | The number of minutes after the hour |
| sec | The number of seconds after the minute |
| isdst | If this is 1, daylight savings time is assumed |
| tm | The timezone (-12 <= tz <= 12) |
Or you can just send them all on one line as the second syntax suggests.
string replace(string s, string from, string to);
string replace(string s, array(string) from, array(string) to);
| array replace(array a, mixed from, mixed to); | |
| mapping replace(mapping a, mixed from, mixed to); |
map_array(index,lambda(mixed x,mixed y) { return y[x]; },data)
Except of course it is a lot shorter and faster. That is, it indexes data on every index in the array index and returns an array with the results.
0: user time 1: system time 2: maxrss 3: idrss 4: isrss 5: minflt 6: minor page faults 7: major page faults 8: swaps 9: block input op. 10: block output op. 11: messages sent 12: messages received 13: signals received 14: voluntary context switches 15: involuntary context switches 16: sysc 17: ioch 18: rtime 19: ttime 20: tftime 21: dftime 22: kftime 23: ltime 24: slptime 25: wtime 26: stoptime 27: brksize 28: stksize
Don't ask me to explain these values, read your system manuals for more information. (Note that all values may not be present though)
When the haystack is a mapping, search tries to find the index connected to the data needle. That is, it tries to lookup the mapping backwards. If needle isn't present in the mapping, zero is returned, and zero_type() will return 1 for this zero.
The callback will receive the signal number as the only argument. See the document for the function 'kill' for a list of signals.
If no second argument is given, the signal handler for that signal is restored to the default handler.
If the second argument is zero, the signal will be completely ignored.
Sort can sort strings, integers and floats in ascending order. Arrays will be sorted first on the first element of each array.
Sort returns its first argument.
Modifiers:
| 0 | Zero pad numbers (implies right justification) |
| ! | Toggle truncation |
| ' ' (space) | pad positive integers with a space |
| + | pad positive integers with a plus sign |
| - | left adjusted within field size (default is right) |
| | | centered within field size |
| = | column mode if strings are greater than field size |
| / | Rough line break (break at exactly field size instead of between words) |
| # | table mode, print a list of '\n' separated word (top-to-bottom order) |
| $ | Inverse table mode (left-to-right order) |
| n | (where n is a number or *) a number specifies field size |
| .n | set precision |
| :n | set field size & precision |
| ;n | Set column width |
| * | if n is a * then next argument is used for precision/field size |
| 'X' | Set a pad string. ' cannot be a part of the pad_string (yet) |
| ~ | Get pad string from argument list. |
| < | Use same arg again |
| ^ | repeat this on every line produced |
| @ | do this format for each entry in argument array |
| > | Put the string at the bottom end of column instead of top |
| _ | Set width to the length of data |
Operators:
| %% | percent |
| %d | signed decimal int |
| %u | unsigned decimal int (doesn't really exist in Pike) |
| %o | unsigned octal int |
| %x | lowercase unsigned hexadecimal int |
| %X | uppercase unsigned hexadecimal int |
| %c | char (or short with %2c, %3c gives 3 bytes etc.) |
| %f | float |
| %g | heuristically chosen representation of float |
| %e | exponential notation float |
| %s | string |
| %O | any type (debug style) |
| %n | nop |
| %t | type of argument |
| %<modifiers>{format%} | do a format for every index in an array. |
The second syntax does not call the system call time() as often, but is only updated in the backed. (when Pike code isn't running)
If useconds is zero, no new alarm is scheduled.
In any event any previously set alarm is canceled.
If the argument is not an int, zero will be returned.
#!/usr/local/bin/pike
mapping records(string:array(string)) = ([
"Star Wars Trilogy" : ({
"Fox Fanfare",
"Main Title",
"Princess Leia's Theme",
"Here They Come",
"The Asteroid Field",
"Yoda's Theme",
"The Imperial March",
"Parade of th Ewoks",
"Luke and Leia",
"Fight with Tie Fighters",
"Jabba the Hut",
"Darth Vader's Death",
"The Forest Battle",
"Finale",
})
]);
void list_records()
{
int i;
array(string) record_names=sort(indices(records));
write("Records:\n");
for(i=0;i<sizeof(record_names);i++)
write(sprintf("%3d: %s\n", i+1, record_names[i]));
}
void show_record(int num)
{
int i;
array(string) record_names=sort(indices(records));
string name=record_names[num-1];
string songs=records[name];
write(sprintf("Record %d, %s\n",num,name));
for(i=0;i<sizeof(songs);i++)
write(sprintf("%3d: %s\n", i+1, songs[i]));
}
void add_record()
{
string record_name=readline("Record name: ");
records[record_name]=({});
write("Input song names, one per line. End with '.' on its own line.\n");
while(1)
{
string song;
song=readline(sprintf("Song %2d: ",sizeof(records[record_name])+1));
if(song==".") return;
records[record_name]+=({song});
}
}
void save(string file_name)
{
string name, song;
object o;
o=Stdio.File();
if(!o->open(file_name,"wct"))
{
write("Failed to open file.\n");
return;
}
foreach(indices(records),name)
{
o->write("Record: "+name+"\n");
foreach(records[name],song)
o->write("Song: "+song+"\n");
}
o->close();
}
void load(string file_name)
{
object o;
string name="ERROR";
string file_contents,line;
o=Stdio.File();
if(!o->open(file_name,"r"))
{
write("Failed to open file.\n");
return;
}
file_contents=o->read();
o->close();
records=([]);
foreach(file_contents/"\n",line)
{
string cmd, arg;
if(sscanf(line,"%s: %s",cmd,arg))
{
switch(lower_case(cmd))
{
case "record":
name=arg;
records[name]=({});
break;
case "song":
records[name]+=({arg});
break;
}
}
}
}
void delete_record(int num)
{
array(string) record_names=sort(indices(records));
string name=record_names[num-1];
m_delete(records,name);
}
void find_song(string title)
{
string name, song;
int hits;
title=lower_case(title);
foreach(indices(records),name)
{
foreach(records[name],song)
{
if(search(lower_case(song), title) != -1)
{
write(name+"; "+song+"\n");
hits++;
}
}
}
if(!hits) write("Not found.\n");
}
int main(int argc, array(string) argv)
{
string cmd;
while(cmd=readline("Command: "))
{
string args;
sscanf(cmd,"%s %s",cmd,args);
switch(cmd)
{
case "list":
if((int)args)
{
show_record((int)args);
}else{
list_records();
}
break;
case "quit":
exit(0);
case "add":
add_record();
break;
case "save":
save(args);
break;
case "load":
load(args);
break;
case "delete":
delete_record((int)args);
break;
case "search":
find_song(args);
break;
}
}
}
array break case catch continue default do else float for foreach function gauge if inherit inline int lambda mapping mixed multiset nomask object predef private program protected public return sscanf static string switch typeof varargs void while
| program | ::= | { definition } |
| definition | ::= | import | inheritance | function_declaration | function_definition | variables | constant | class_def |
| import | ::= | modifiers import constant_identifier ";" |
| inheritance | ::= | modifiers inherit program_specifier [ ":" identifier ] ";" |
| function_declaration | ::= | modifiers type identifier "(" arguments ")" ";" |
| function_definition | ::= | modifiers type identifier "(" arguments ")" block |
| variables | ::= | modifiers type variable_names ";" |
| variable_names | ::= | variable_name { "," variable_name } |
| variable_name | ::= | { "*" } identifier [ "=" expression2 ] |
| constant | ::= | modifiers constant constant_names ";" |
| constant_names | ::= | constant_name { "," constant_name } |
| constant_name | ::= | identifier "=" expression2 |
| class_def | ::= | modifiers class [ ";" ] |
| class | ::= | class [ identifier ] "{" program "}" |
| modifiers | ::= | { static | private | nomask | public | protected | inline } |
| block | ::= | "{" { statement } "}" |
| statement | ::= | expression2 ";" | cond | while | do_while | for | switch | case | default | return | block | foreach | break | continue | ";" |
| cond | ::= | if statement [ else statement ] |
| while | ::= | while "(" expression ")" statement |
| do_while | ::= | do statement while "(" expression ")" ";" |
| for | ::= | for "(" [ expression ] ";" [ expression ] ";" [ expression ] ")" statement |
| switch | ::= | switch "(" expression ")" block |
| case | ::= | case expression [ ".." expression ] ":" |
| default | ::= | default ":" |
| foreach | ::= | foreach "(" expression ":" expression6 ")" statement |
| break | ::= | break ";" |
| continue | ::= | continue ";" |
| expression | ::= | expression2 { "," expression2 } |
| expression2 | ::= | { lvalue ( "=" | "+=" | "*=" | "/=" | "&=" | "|=" | "^=" | "<<=" | ">>=" | "%=" ) } expression3 |
| expression3 | ::= | expression4 '?' expression3 ":" expression3 |
| expression4 | ::= | { expression5 ( "||" | "&&" | "|" | "^" | "&" | "==" | "!=" | ">" | "<" | ">=" | "<=" | "<<" | ">>" | "+" | "*" | "/" | "%" ) } expression5 |
| expression5 | ::= | expression6 | "(" type ")" expression5 | "--" expression6 | "++" expression6 | expression6 "--" | expression6 "++" | "~" expression5 | "-" expression5 |
| expression6 | ::= | string | number | float | catch | gauge | typeof | sscanf | lambda | class | constant_identifier | call | index | mapping | multiset | array | parenthesis | arrow |
| number | ::= | digit { digit } | "0x" { digits } | "'" character "'" |
| float | ::= | digit { digit } "." { digit } |
| catch | ::= | catch ( "(" expression ")" | block ) |
| gauge | ::= | gauge ( "(" expression ")" | block ) |
| sscanf | ::= | sscanf "(" expression2 "," expression2 { "," lvalue } ")" |
| lvalue | ::= | lambda expression6 | type identifier |
| lambda | ::= | lambda "(" arguments ")" block |
| constant_identifier | ::= | identifier { "." identifier } |
| call | ::= | expression6 "(" expression_list ")" |
| index | ::= | expression6 "[" expression [ ".." expression ] "]" |
| array | ::= | "({" expression_list "})" |
| multiset | ::= | "(<" expression_list ">)" |
| mapping | ::= | "([" [ expression : expression { "," expression ":" expression } ] [ "," ] "])" |
| arrow | ::= | expression6 "->" identifier |
| parenthesis | ::= | "(" expression ")" |
| expression_list | ::= | [ splice_expression { "," splice_expression } ] [ "," ] |
| splice_expression | ::= | [ "@" ] expression2 |
| type | ::= | ( int | string | float | program | object [ "(" program_specifier ")" ] | mapping [ "(" type ":" type ")" | array [ "(" type ")" ] | multiset [ "(" type ")" ] | function [ function_type ] ) { "*" } |
| function_type | ::= | "(" [ type { "," type } [ "..." ] ")" |
| arguments | ::= | [ argument { "," argument } ] [","] |
| argument | ::= | type [ "..." ] [ identifier ] |
| program_specifier | ::= | string_constant | constant_identifier |
| string | ::= | string_literal { string_literal } |
| identifier | ::= | letter { letter | digit } | "`+" | "`/" | "`%" | "`*" | "`&" | "`|" | "`^" | "`~" | "`<" | "`<<" | "`<=" | "`>" | "`>>" | "`>=" | "`==" | "`!=" | "`!" | "`()" | "`-" | "`->" | "`->=" | "`[]" | "`[]=" |
| letter | ::= | "a"-"z" | "A"-"Z" | "_" |
| digit | ::= | "0"-"9" |
$ gunzip -d Pike-v0.5.tar.gz $ tar xvf Pike-v0.5.tarNow you have a directory called Pike-v0.5. Please read the README file in the new directory since newer versions can contain information not available at the time this book was written.
Now, to compile Pike, the following three commands should be enough.
$ cd Pike-v0.5/src $ ./configure --prefix=/dir/to/install/pike $ makeThey will (in order) change directory to the source directory. Configure will then find out what features are available on your system and construct makefiles. You will see a lot of output after you run configure. Do not worry, that is normal. It is usually not a good idea to install Pike anywhere but in /usr/local (the default) since Pike scripts written by other people will usually assume that's where Pike is. However, if you do not have write access to /usr/local you will have to install Pike somewhere else on your system.
After that make will actually compile the program. After compilation it is a good idea to do make verify to make sure that Pike is 100% compatible with your system. Make verify will take a while to run and use a lot of CPU, but it is worth it to see that your compilation was successful. After doing that you should run make install to install the Pike binaries, libraries and include files in the directory you selected earlier.
You are now ready to use Pike.
Index
`
A
B
C
D
E
F
G
H
I
K
L
M
N
O
P
Q
R
S
T
U
V
W
X
Y
Z
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}